Soluții
How to merge Audio Files on Windows 11
[mai mult...]Can Google Wallet Work without Wi-Fi or Mobile Data?
[mai mult...]How to use Google Wallet to store Event Tickets and boarding passes
[mai mult...]Cum se instalează Fast API cu MongoDB pe Ubuntu 24.04
FastAPI este un cadru web bazat pe Python pentru crearea de servicii API. Este un cadru modern, rapid și de înaltă performanță care acceptă operațiuni asincrone.
Pentru a începe cu acest ghid, asigurați-vă că aveți următoarele:
- Un sistem Ubuntu 24.04
- Un utilizator non-root cu privilegii de administrator.
Mai întâi, rulați comanda de mai jos pentru a vă actualiza indexul pachetului și instalați „gnupg” și „curl” în sistemul dumneavoastră.
sudo apt update && sudo apt install gnupg curl -y
Executați comanda de mai jos pentru a adăuga cheia GPG pentru serverul MongoDB.
curl -fsSL https://www.mongodb.org/static/pgp/server-8.0.asc | \ sudo gpg -o /usr/share/keyrings/mongodb-server-8.0.gpg \ --dearmor
Adăugați depozitul MongoDB folosind comanda de mai jos.
echo „deb [ arch=amd64,arm64 signed-by=/usr/share/keyrings/mongodb-server-8.0.gpg ] https://repo.mongodb.org/apt/ubuntu noble/mongodb-org/8.0 multiverse” | sudo tee /etc/apt/sources.list.d/mongodb-org-8.0.list
După ce depozitul este adăugat, rulați următoarea comandă pentru a vă reîmprospăta indexul pachetului și pentru a instala serverul MongoDB. Introduceți „Y” pentru a confirma instalarea.
sudo apt update && sudo apt install mongodb-org

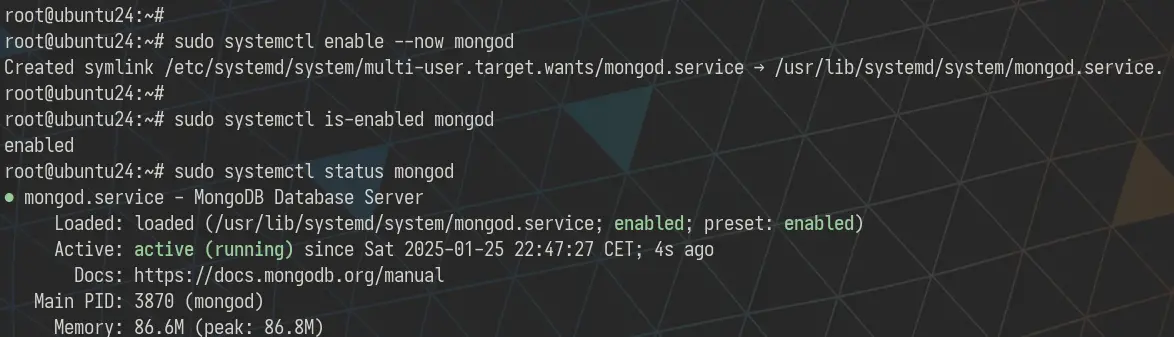
Când instalarea este finalizată, porniți și activați serviciul MongoDB „mongod”, apoi verificați starea serviciului MongoDB pentru a vă asigura că rulează.
sudo systemctl enable --acum mongod sudo systemctl status mongod
Puteți vedea mai jos că serverul MongoDB rulează.
În plus, vă puteți conecta la serverul MongoDB cu comanda „mongosh” de mai jos. Pentru a ieși, apăsați Ctrl+d.
mongosh
Cu MongoDB instalat, veți instala pachetele Python și veți configura directorul proiectului și mediul virtual.
Instalați modulele Python, Pip și Venv cu următoarea comandă. Introduceți „Y” pentru a confirma instalarea.
sudo apt install python3 python3-pip python3-venv
Odată ce instalarea este finalizată, conectați-vă la utilizatorul dvs.
su - username
Acum creați un nou director „ ~/app ” și mutați-vă în el. Acest director va fi folosit pentru a stoca proiectul dvs. FastAPI.
mkdir -p ~/app; cd ~/app
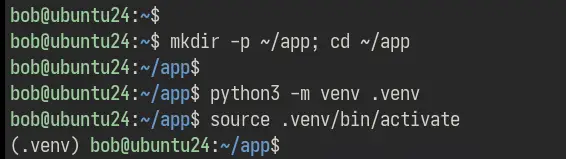
Executați comanda de mai jos pentru a crea un nou mediu virtual „ venv ” și activați-l. Cu aceasta, promptul dumneavoastră shell va deveni ca „ (venv) user@hostname ”.
python3 -m venv .venv
sursă .venv/bin/activate
De aici, mediul tău de lucru trebuie să fie în mediul virtual „venv”. Vă puteți deconecta de la „venv” folosind comanda de mai jos.
deactivate
Acum că ați creat și activat mediul virtual Python, să instalăm FastAPI și să creăm structura proiectului.
Cu comanda „pip3”, executați-o pentru a instala pachetele „fastapi” și „uvicorn”.
pip3 install fastapi uvicorn
- „fastapi” este principalul cadru web FastAPI pentru construirea de API-uri în Python
- „Uvicorn” este implementarea serverului web ASGI (Asynchronous Server Gateway Interface) în Python.
După finalizarea instalării, creați noi fișiere și directoare cu următoarea comandă.
mkdir -p server/{models,routes}
touch main.py server/{app.py,database.py} server/models/itemModels.py server/routes/item.py
Mai jos este structura proiectului nostru FastAPI.
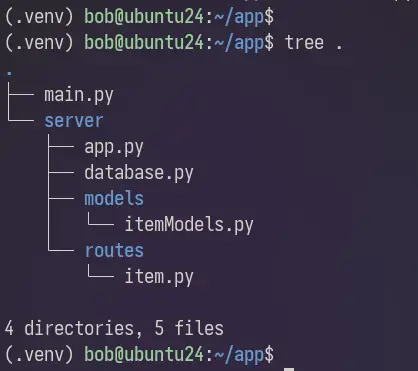
server/app.py
Acum că proiectul dvs. este gata, să modificăm fișierul „server/app.py”, care este principala aplicație a proiectului dumneavoastră FastAPI.
Deschideți fișierul „ app.py ” cu editorul de text și copiați următorul script.
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello FastAPI!"}
- Importați modulul FastAPI în proiectul dvs. și legați-l la variabila „aplicație”.
- Creați o nouă funcție „rădăcină” care returnează „Hello FastAPI!”
- Funcția „rădăcină” a răspuns la metoda GET de pe URL-ul rădăcină
- „async” marchează funcția dumneavoastră ca o funcție asincronă și ar putea folosi „wait” în corpul său atunci când este apelată
principal.py
În această secțiune, vom modifica fișierul „main.py” care va fi folosit pentru a rula proiectul FastAPI prin „uvicorn” (server web ASGI în Python).
Acum deschideți și modificați scriptul „ main.py ” și introduceți următorul cod.
import uvicorn
if __name__ == "__main__":
uvicorn.run ("server.app:app", host="0.0.0.0", port=8080, reload=True)
- Importați modulul „uvicorn”.
- Când scriptul „main.py” este executat, acesta va încărca „aplicația” sau modulul FastAPI în „server/app.py”
- FastAPI va rula pe „0.0.0.0” cu portul „8080”
- Activați reîncărcarea automată când codul se schimbă prin „reload=True”
Rulați proiectul FastAPI
Acum că proiectul dvs. este gata, să rulăm primul proiect FastAPI. Executați scriptul „main.py” după cum urmează și FastAPI-ul dumneavoastră va rula pe sistemul dumneavoastră.
python3 main.py
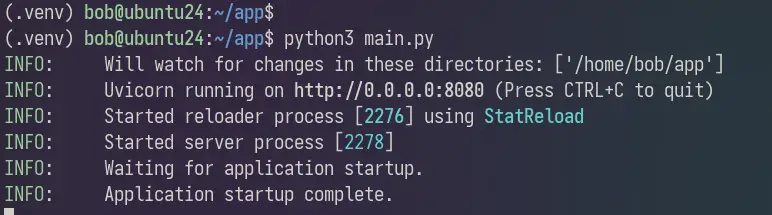
Acum deschideți browserul web și vizitați http://SERVERIP:8080/ . Dacă instalarea a reușit, veți vedea „Hello FastAPI!” mesaj. Îl poți accesa și prin „curl” din terminal.
În cele din urmă, puteți accesa documentația API pe http://SERVERIP:8080/docs > care este furnizată de Swagger UI.

În acest ghid, veți crea un API de bază cu FastAPI și MongoDB. API-ul dvs. ar trebui să poată face CRUD cu serverul de baze de date MongoDB. În ceea ce privește acest pas, vă veți conecta proiectul la serverul MongoDB.
Mai întâi, rulați comanda „pip3” de mai jos pentru a instala driverul MongoDB „ motor ” în proiectul dumneavoastră. „motor” oferă acces API non-blocant și bazat pe corutine la serverul MongoDB.
pip3 install motor
server/database.py
După ce modulul „ motor ” este instalat, să modificăm scriptul „ server/database.py ”. Deschideți fișierul „server/database.py” cu editorul de text și introduceți următorul script. Acesta va fi folosit pentru a vă conecta la serverul MongoDB prin modulul „motor”.
from motor.motor_asyncio import AsyncIOMotorClient
MONGODB_HOST = "mongodb://localhost:27017"
connection = AsyncIOMotorClient(MONGODB_HOST)
database = connection.items
item_collection = database.get_collection("item_collection")
- Importați „AsyncIOMotorClient” din „motor.motor_asyncio”
- Creați o nouă constantă „MONGODB_HOST” și indicați către serverul MongoDB „mongodb://localhost:27017”
- Conectați-vă la serverul MongoDB prin variabila „conexiune”.
- Conectați-vă la baza de date „articole” prin variabila „bază de date”.
- Accesați colecțiile din baza de date cu variabila „item_collection”.
Crearea modelului bazei de date cu pydantic
În această secțiune, vă veți proiecta datele prin „ pydantic ”, care oferă modelare pentru baza noastră de date MongoDB.
Instalați modulul „pydantic” cu comanda „pip3” de mai jos. Modulul „ pydantic ” este o bibliotecă de validare a datelor care vă permite să creați schema bazei de date prin model.
pip3 install pydantic
Acum deschideți fișierul „ server/models/itemModels.py ” cu editorul de text și copiați următorul script.
from pydantic import BaseModel, Field
from typing import Optional
class Item(BaseModel):
name: str
category: str
stocks: int
price: int = Field(gt=0)
class Config:
json_schema_extra = {
"example": {
"name": "Company Smart Watch",
"category": "smartwatch",
"stocks": 10,
"price": 1000,
}
}
class ItemUpdate(BaseModel):
name: Optional[str] = None
category: Optional[str] = None
stocks: Optional[int] = None
price: Optional[int] = None
class Config:
json_schema_extra = {
"example": {
"name": "New Smart watch",
"category": "new-smartwatch",
"stocks": 5,
"price": 500,
}
}
- Importați modulele „BaseModel” și „Field” din „pydantic”
- Importați modulul „Opțional” din „tastare”
- Creați următoarea schemă de bază de date „Articol” pentru FastAPI:
- „nume” și „categorie” cu șir de tip
- „stocuri” și „preț” cu categoria întreg
- „prețul” trebuie să fie mai mare decât 0
- Extindeți modelul de date prin clasa „Config” oferind un exemplu de date pe care utilizatorul le poate include în cerere
- Creați următoarea schemă „ItemUpdate” cu fiecare câmp opțional.
Adăugarea de operațiuni CRUD
În acest moment, ați creat o conexiune la serverul MongoDB și ați creat schema bazei de date prin „pydantic”. Să trecem la crearea operațiunilor CRUD cu FastAPI și MongoDB.
Deschideți din nou scriptul „ server/database.py ” și creați o nouă funcție „ item_helper ” cu tipul „ dict ”. Apelați această funcție pentru a obține date detaliate despre un articol.
def item_helper(item) -> dict:
return {
"id": str(item["_id"]),
"name": item["name"],
"category": item["category"],
"stocks": item["stocks"],
"price": item["price"],
}
Adăugați următoarea linie pentru a importa modulul „ ObjectId ” din „bson.objectid”. „ ObjectId ” face parte din tipul de date din BSON, pe care MongoDB îl folosește pentru stocarea datelor și reprezentarea datelor JSON.
from bson.objectid import ObjectId
Creați un articol
În primul rând, veți crea o funcție asincronă care va putea adăuga date noi la baza de date MongoDB.
Creați o nouă funcție „a dd_item ” ca următorul:
# Adăugați un articol nouasync def add_item(item_details: dict) -> dict : item = await item_collection.insert_one(item_details) new_item = await item_collection.find_one({"_id": item.inserted_id}) return item_helper(new_item)
- Funcția „add_item” acceptă datele din dicționar ale detaliilor articolului dvs
- Prin „item_collection” pentru a accesa documentele din baza de date și pentru a executa interogarea „insert_one” pentru a adăuga un nou articol
- Noul articol va fi tipărit după operarea cu succes
Preluați toate articolele
În al doilea rând, veți crea o nouă funcție „get_items” care va putea prelua toate elementele disponibile din baza de date.
Creați o nouă funcție „ get_items ” pentru a prelua toate articolele din MongoDB.
# preluati toate elementeleasync def get_items(): items = [] async for item in item_collection.find(): items.append(item_helper(item)) return items
- Veți crea o listă goală de „articole”
- Folosind interogarea „find()” pentru a căuta toate datele și a le trece în buclă
- Fiecare articol va fi adăugat la lista „articole” prin metoda „adăugați”.
- După finalizarea buclei, articolele dvs. vor fi afișate
Preluați un articol specific bazat pe id
Apoi, veți crea o nouă funcție care va putea prelua date pentru un anumit selector „id”. Aceasta vă va afișa date detaliate despre anumite articole.
Creați o nouă funcție „ get_item ” pentru a prelua date despre anumite articole. Funcția „get_item” va accepta un șir de „id” ca selector și va returna un dicționar.
# preluare un anumit articol
async def get_item(id: str) -> dict:
item = await item_collection.find_one({"_id": ObjectId(id)})
if item:
return item_helper(item)
return "Articol nu a fost găsit."
- Interogarea „find_one()” va fi folosită pentru a prelua date bazate pe „id”
- Dacă se găsește un articol, detaliile vor fi afișate folosind formatul de dicționar „item_helper”.
- Dacă articolul nu este disponibil, răspunsul este „Articol nu a fost găsit”
Actualizați un articol
Acum veți crea o nouă funcție pentru actualizarea unui articol. De asemenea, vă puteți actualiza parțial articolul prin API.
Definiți noua funcție „ change_item ” ca următoarele coduri:
# update item
async def change_item(id: str, data: dict):
if len(data) < 1:
return "Please input your data"
find_item = await item_collection.find_one({"_id": ObjectId(id)})
if find_item:
item_update = await item_collection.update_one({"_id": ObjectId(id)}, {"$set": data})
if item_update:
return True
return False
- Funcția „change_item” ia două argumente, „id-ul” articolului țintă și „data” ca date noi
- Dacă datele sunt goale sau „< 1”, operațiunea s-a încheiat
- Această funcție va găsi un articol pe baza selectorului „id”.
- Dacă „id-ul” este găsit, „item_update” va fi executat
- Dacă „item_update” are succes, returnați „True” sau returnați „False” dacă nu
Ștergeți un articol
În cele din urmă, veți crea funcția „delete_item” pentru ștergerea articolelor printr-un anumit selector. Pentru a șterge un articol, vom crea funcția „ delete_item ” și vom folosi selectorul „id” după cum urmează:
# ștergeți un articol
async def delete_item(id: str):
item = await item_collection.find_one({"_id": ObjectId(id)})
if item:
await item_collection.delete_one({"_id": ObjectId(id)})
return(f'Item {id} deleted.')
return "Articol negăsit.') return
- Interogarea „find_one()” va căuta un articol pe baza „id-ului” furnizat
- Dacă elementul este găsit, acesta va fi șters prin interogarea „delete_one()” și va returna „Id-ul articolului șters”
- Dacă articolul nu este disponibil, va fi afișat „Articol negăsit”.
Adăugarea rutelor pentru operațiuni CRUD
În acest moment, am creat funcții asincrone pentru operarea CRUD cu FastAPI. Acum să creăm ruta sau punctul final pentru fiecare operațiune. Editați fișierul „ server/routes/item.py ” folosind editorul preferat.
server/routes/item.py
Mai întâi, adăugați modulele „ APIRouter ” și „ Corps ” din „fastapi”. Apoi, adăugați „ jsonable_encode ” din „fastapi.encoders”.
from fastapi import APIRouter, Body from fastapi.encoders import jsonable_encoder
Importați fiecare funcție din fișierul „database.py”.
from server.database import ( add_item, get_items, get_item, change_item, delete_item, )
Importați modelele „Item” și „ItemUpdate” din fișierul „itemModels.py”.
from server.models.itemModels import ( Item, ItemUpdate, )
Apelați clasa „APIRouter” prin variabila „router”.
router = APIRouter()
Traseu pentru adăugarea unui articol nou
Acum să adăugăm o rută pentru adăugarea de elemente noi. În acest exemplu, puteți adăuga un nou articol prin POST la adresa URL „ /item ”.
Adăugați următoarele linii pentru a configura rute pentru adăugarea de elemente noi. Fiecare POST către adresa URL rădăcină a articolului va fi tratată ca inserare date noi.
# add new item operation
@router.post("/")
async def add_item_data(item: Item = Body(...)):
item = jsonable_encoder(item)
new_item = await add_item(item)
return new_item
- Funcția „add_item_data” acceptă schema „Articol”, care va face parte din „Corps” la cererea dvs.
- Articolul dvs. va fi convertit în format de dicționar prin „jsonable_encoder”
- Introduceți datele din dicționar prin funcția „add_item” (consultați database.py) deasupra variabilei „new_item”
- Returnați datele introduse „new_item” ca răspuns
Traseu pentru a obține toate articolele
Adăugați următorul script pentru a configura o rută pentru preluarea datelor. Fiecare solicitare GET către adresa URL a elementului rădăcină va prelua toate datele dvs.
# obține toate articolele disponibile
@router.get("/")
asincron def get_item_data():
items = await get_items()
if items:
return items
return "Niciun articol disponibil."
- Creați funcția „get_item_data” care va executa funcția „get_item” din fișierul „database.py”
- Dacă articolele sunt disponibile, veți primi lista tuturor articolelor dvs
- Dacă nu există niciun articol, veți primi răspunsul „Niciun articol disponibil”.
Traseu pentru a obține un articol specific
Pentru a obține detalii despre un anumit articol, vom folosi „id” ca selector. Fiecare cerere GET către „/id” va returna un articol detaliat al „id-ului” solicitat.
# Afișați detaliile articolului prin ID-ul
@router.get("/{id}")
asincron def get_item_details(id):
item_details = await get_item(id)
if item_details:
return item_details
return "Articol nu a fost găsit."
- Funcția „get_item_details” va fi creată și va transmite „id” de la adresa URL
- Funcția „get_item” (vezi database.py) va fi apelată și va trece, de asemenea, „id” ca argument
- Dacă articolul este găsit, vor fi afișate detaliile articolului
- Dacă niciun articol cu acel „id” specific, veți primi „Articol nu a fost găsit”
Rută pentru actualizarea unui articol
Copiați următorul cod pentru a seta ruta pentru elementul actualizat:
# Update Item
@router.put("/{id}")
asincron def update_item(id: str, data: ItemUpdate = Body(...)):
data = {k:v for k, v in data.dict().items() if v is not None}
updated_item = await change_item(id, data)
if updated_item}
return: {f'item}
return. "Eroare"
- Funcția „update_item” va lua două argumente, „id” ca selector și „data”, care se bazează pe modelul „ItemUpdate”
- Datele vor fi verificate în variabila „date”.
- „updated_item” va executa funcția „change_item” din fișierul „database.py”
- Dacă actualizarea a reușit, veți vedea rezultatul „Succes”
Rută pentru ștergerea unui articol
Introduceți următoarele rânduri pentru a crea funcția „remove_item” pentru ștergerea articolelor. Fiecare operație DELETE la un anumit „/id” va elimina elementul potrivit cu „id”.
# ștergeți elementul prin id
@router.delete("/{id}")
asincron def remove_item(id):
item_to_delete = await delete_item(id)
if item_to_delete:
return item_to_delete
return{f'Item {id} Nu este disponibil.'}
- Funcția „remove_item” va executa „delete_item” și va trece selectorul „id”
- Operația de ștergere va fi stocată și executată prin variabila „item_to_delete”.
- Când un articol nu este disponibil, veți primi returnarea „Id articol nu este disponibil”
server/app.py
- Acum că ați terminat fișierul „server/routes/item.py”, să-l includem în „server/app.py”.
- Deschideți fișierul „ app.py ” folosind editorul de text.
- Importați „routerul” din fișierul „ server/routes/item.py ” ca „ ItemRouter ”.
de la server.routes.item import router ca ItemRouter
Introduceți „ItemRouter” cu prefixul implicit „ /item ”. Operațiunile CRUD vor fi gestionate prin adresa URL „ /item ”.
app.include_router(ItemRouter, tags="["Articol"], prefix="/item")
Acum punctul final CRUD va fi disponibil la următoarele:
- Adăugați un articol nou: POST la „ /item ”
- Preluați toate articolele: GET la „ /item ”
- Preluați un anumit articol: GET la „/item/id” . „ID” este generat de MongoDB
- Actualizați elementul: PUT la „/item/id”
- Ștergeți elementul: DELETE în „/item/id”
Testați operațiunile CRUD
În primul rând, asigurați-vă că proiectul dvs. FastAPI rulează sau puteți executa scriptul „main.py” în felul următor:
python3 main.py
Navigați prin http://SERVERIP:8080/docs și veți vedea fiecare rută pe care ați creat-o.

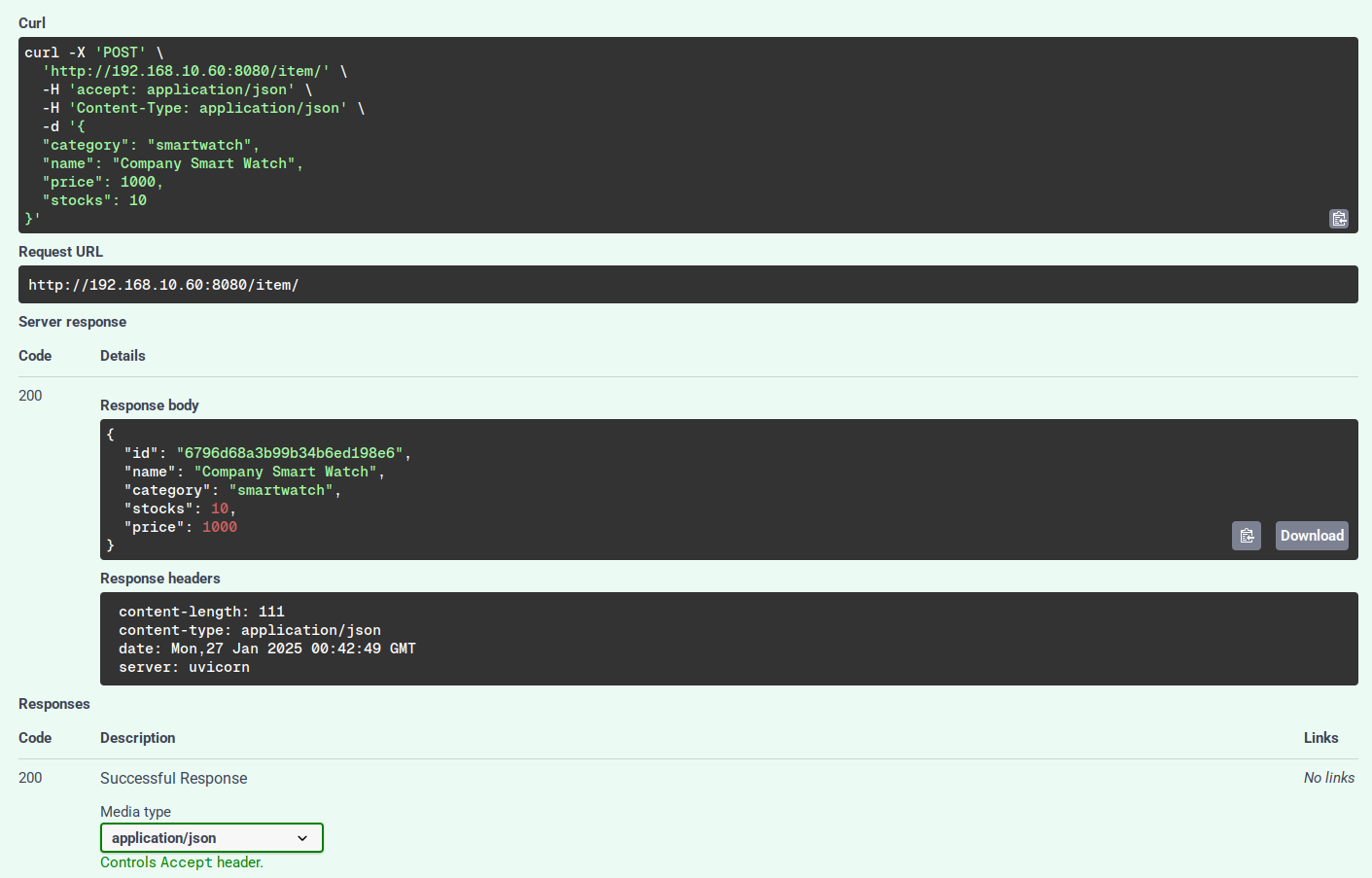
Mai jos este un exemplu de adăugare a unui articol nou.

Preluați toate articolele disponibile prin API.
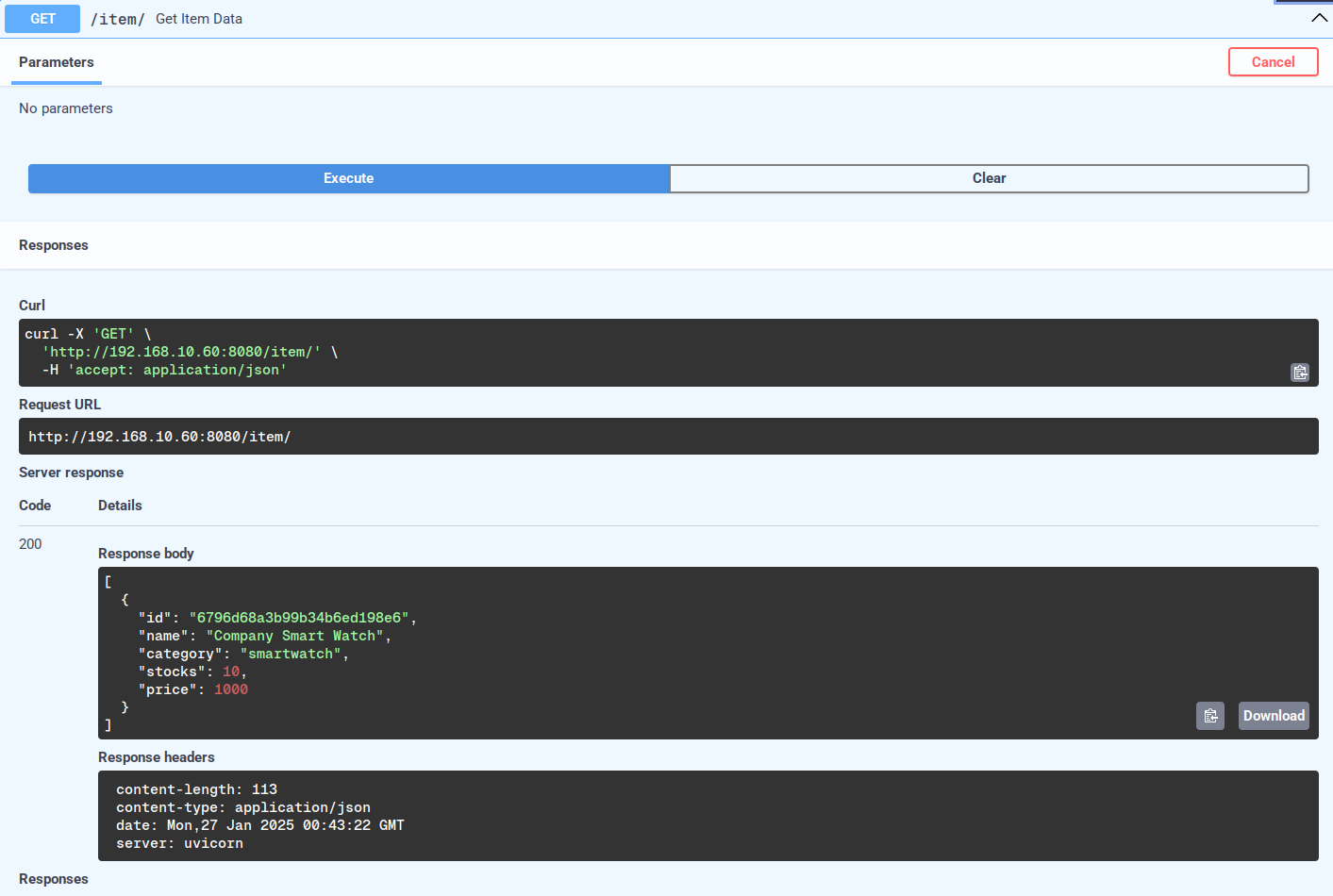
Preluați anumite elemente prin selectorul „id”.
Actualizați datele parțiale din anumite articole.
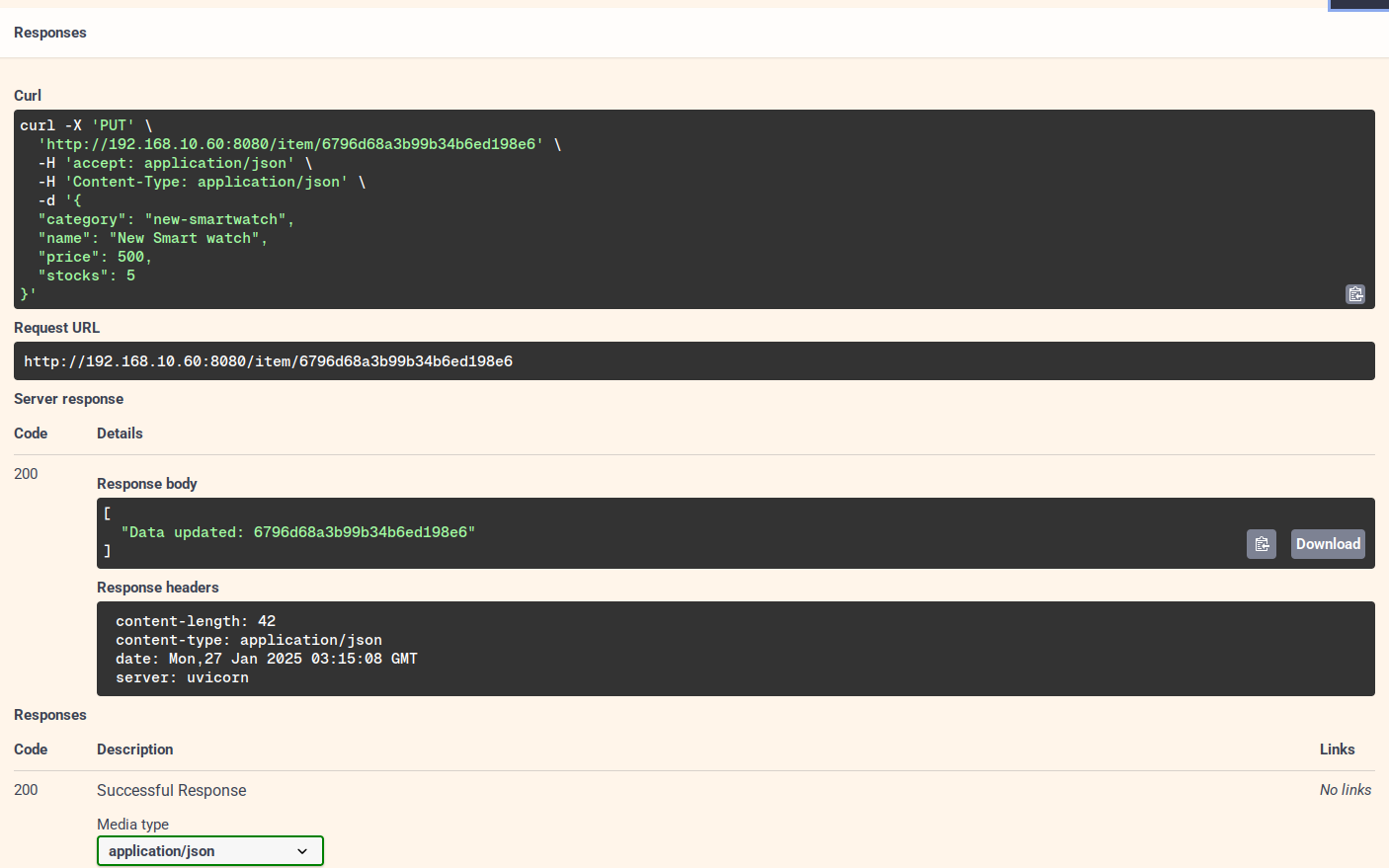
Mai jos sunt datele actualizate.

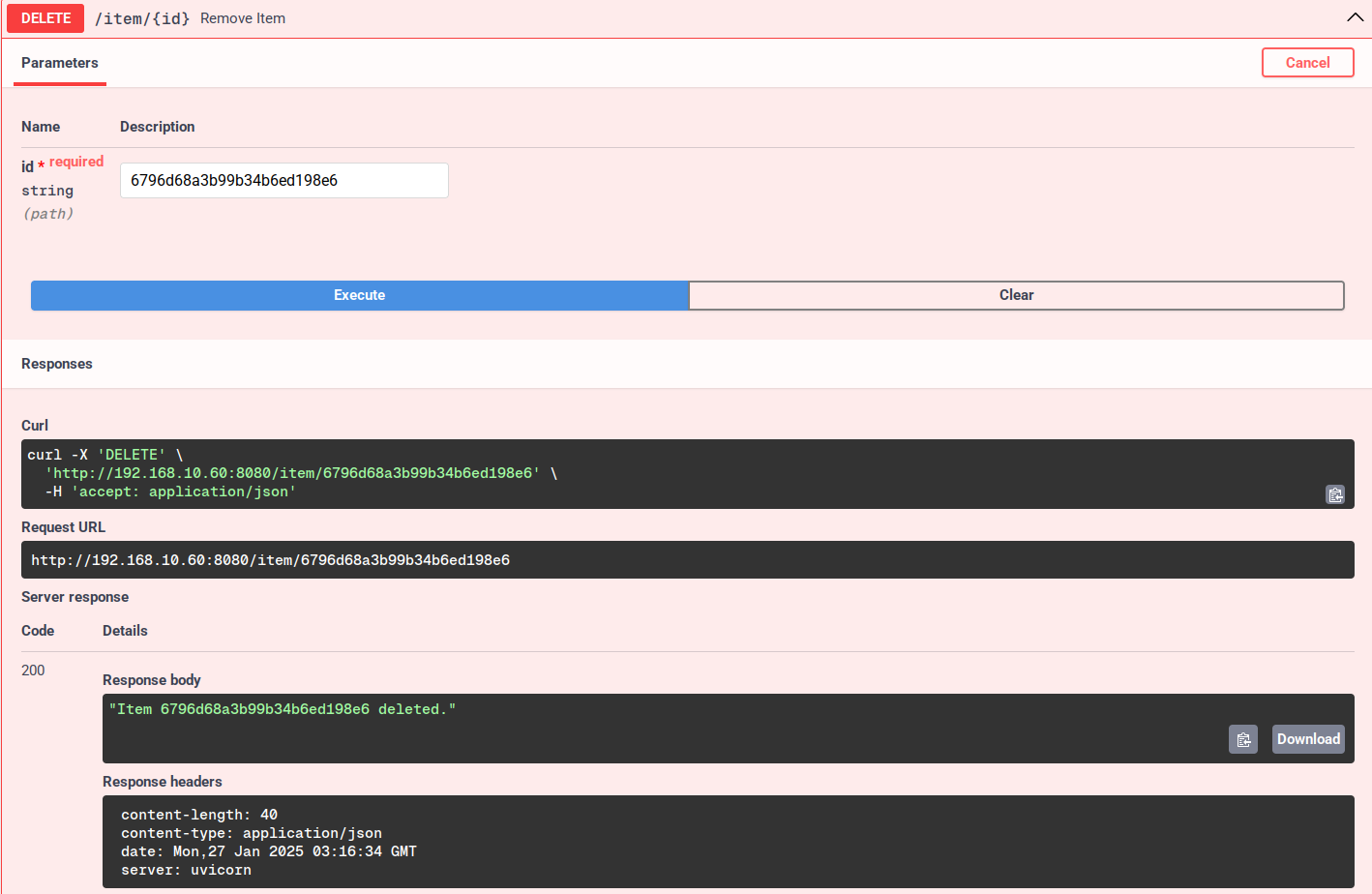
Mai jos este operația de ștergere prin selectorul „id”.
Cum se instalează Apache Solr pe un server Ubuntu 24.04
Apache Solr este o platformă de căutare open-source construită pe Apache Lucene, concepută pentru a crea capabilități puternice de căutare și indexare a aplicațiilor. Oferă căutare avansată full-text, căutare fațetă, indexare în timp real și căutare distribuită, ceea ce îl face o alegere populară pentru construirea de motoare de căutare și sisteme de recuperare a datelor.
Solr este extrem de scalabil și optimizat pentru volume mari de date, adesea folosit în mediile de întreprindere pentru sarcini precum căutarea pe site-uri web, comerțul electronic și analiza big data. API-ul său asemănător REST permite integrarea ușoară cu alte sisteme și acceptă funcții precum evidențierea sugestiilor de interogări și căutarea geospațială. Flexibilitatea, performanța și suportul comunității Solr au făcut din acesta o soluție de top pentru organizațiile care au nevoie de funcționalități de căutare robuste.
Înainte de a instala Apache Solr, haideți să pregătim și să configuram sistemul nostru Ubuntu prin creșterea shmmax și nr_hugepages în parametrul kernelului, apoi mărind fișierele și procesele deschise maxime implicite.
Executați comanda de mai jos pentru a crește shmmax și nr_hugepages pe serverul Ubuntu.
sudo echo 4294967295 > /proc/sys/kernel/shmmax sudo echo 1536 > /proc/sys/vm/nr_hugepages
Acum rulați comanda de mai jos pentru a modifica fișierul /etc/security/limits.conf .
sudo nano /etc/security/limits.conf
Creșteți numărul maxim de fișiere și procese deschise pentru utilizatorul solr cu următoarea configurație.
solr soft nofile 65000 solr hard nofile 65000 solr soft nproc 65000 solr hard nproc 65000
Salvați fișierul și ieșiți din editor.
Instalarea Java OpenJDK
Acum că v-ați configurat sistemul, să instalăm Java OpenJDK în sistemul nostru. Apache Solr necesită cel puțin Java 11 instalat pe sistemul dvs. și, pentru acest ghid, vom folosi pachetul implicit-jdk care oferă cea mai recentă versiune Java OpenJDK stabilă.
Mai întâi, actualizați indexul pachetului Ubuntu cu următoarele.
actualizare sudo apt
Acum instalați pachetul implicit-jdk folosind comanda de mai jos. Introdu Y pentru a confirma instalarea.
sudo apt install default-jdk
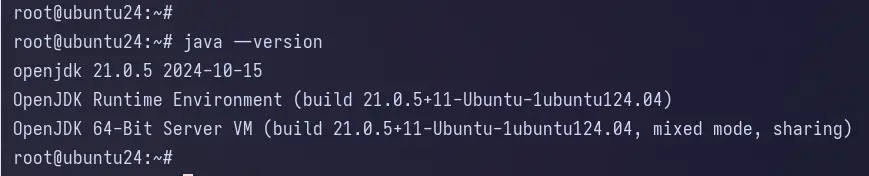
După finalizarea instalării, verificați versiunea Java cu următoarea comandă.
java --versiune
Puteți vedea mai jos că Java 21 este instalat.
Instalarea Apache Solr
Acum că sistemul dumneavoastră Ubuntu este configurat și Java OpenJDK instalat, să începem instalarea Apache Solr. În acest ghid, veți instala Apache Solr folosind scriptul de instalare furnizat de pachetul Solr.
Pentru a începe, rulați comanda de mai jos pentru a instala instrumente de bază, cum ar fi curl , lsof și bc .
sudo apt install curl lsof bc
Acum descărcați pachetul binar Apache Solr cu comanda wget de mai jos.
wget https://www.apache.org/dyn/closer.lua/solr/solr/9.7.0/solr-9.7.0.tgz?action=download
Redenumiți pachetul Apache Solr și extrageți scriptul de instalare install_solr_service.sh folosind comanda de mai jos.
mv solr-9.7.0.tgz?action=download solr-9.7.0.tgz tar -xf tar xzf solr-9.7.0.tgz solr-9.7.0/bin/install_solr_service.sh --strip-components=2
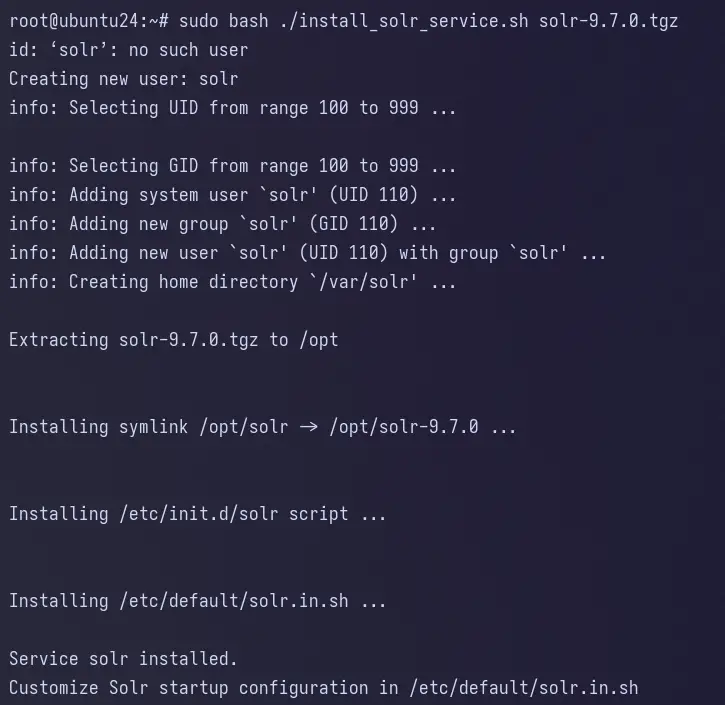
Acum executați scriptul install_solr_service.sh pentru a instala Apache Solr.
sudo bash ./install_solr_service.sh solr-9.7.0.tgz
Puteți vedea mai jos instalarea detaliată a Apache Solr.
- Directorul de instalare implicit se află în directorul /opt/solr .
- Noul utilizator solr este creat automat.
- Noul fișier de servicii solr.service este creat pentru gestionarea serviciului Apache Solr.
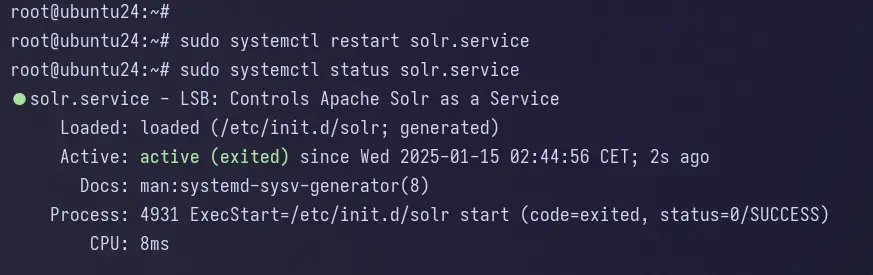
Acum verificați starea solr cu comanda de mai jos. Puteți vedea solr cu starea active(exited) , ceea ce înseamnă că serviciul rulează, dar systemd nu poate găsi niciun fișier de monitorizat.
sudo systemctl status solr
De asemenea, puteți verifica porturile deschise de pe sistemul dvs. folosind comanda ss de mai jos. Apache Solr ar trebui să ruleze pe portul 8893.
ss -tulpn
Configurarea Apache Solr
Acum că Apache Solr este instalat, să-l configuram prin modificarea parametrilor Apache Solr din scriptul /etc/default/solr.in.sh. Apoi, creșteți memoria maximă implicită și adresa IP folosită pentru a rula Apache Solr.
Deschideți fișierul de configurare Solr /etc/default/solr.in.sh folosind editorul vim .
sudo vim /etc/default/solr.in.sh
Schimbați opțiunea implicită SOLR_HEAP cu alocarea maximă de memorie pentru Apache Solr. În acest exemplu, vom folosi 4 GB de RAM.
SOLR_HEAP="4g"
Introduceți adresa dvs. IP în opțiunile SOLR_HOST și SOLR_JETTY_HOST . În acest exemplu, Apache Solr va rula pe adresa IP locală 192.169.10.60.
SOLR_HOST="192.168.10.15" SOLR_JETTY_HOST="192.168.10.15"
Acum rulați comanda systemctl de mai jos pentru a reporni serviciul Apache Solr și a aplica modificările.
sudo systemctl restart solr
Puteți verifica portul deschis și ce adresă IP este folosită de Apache Solr cu comanda ss de mai jos.
ss -tulpn

Securizarea Apache Solr cu autentificare
După configurarea Apache Solr, următorul pas este să vă asigurați implementarea. În acest exemplu, vom folosi autentificarea de bază pentru a securiza Apache Solr. Acest lucru se poate face prin crearea unui nou fișier /var/solr/data/security.json .
Creați o nouă configurație /var/solr/data/security.json cu editorul vim.
sudo vim /var/solr/data/security.json
Introduceți configurația de mai jos pentru a configura autentificarea pentru Apache Solr și creați un nou utilizator solr cu parola solrRocks .
{
"authentication":{
"blockUnknown": true,
"class":"solr.BasicAuthPlugin",
"credentials":{"solr":"IV0EHq1OnNrj6gvRCwvFwTrZ1+z1oBbnQdiVC3otuq0= Ndd7LKvVBAaZIF0QAVi1ekCfAJXr1GGfLtRUXhgrF8c="},
"realm":"Utilizatorii mei Solr",
"forwardCredentials": false
},
"authorization":{
"class":"solr.RuleBasedAuthorizationPlugin",
"permissions":":", "permissions":":", "permissions":":",
"user-role":{"solr":"admin"}
}
}
Salvați fișierul și ieșiți din editor.
Acum rulați comanda systemctl de mai jos pentru a reporni serviciul solr și a aplica modificările.
sudo systemctl restart solr
Apoi, deschideți browserul web și vizitați instalarea Apache Solr http://192.168.10.60:8983/. Veți fi redirecționat către pagina de conectare Apache Solr.
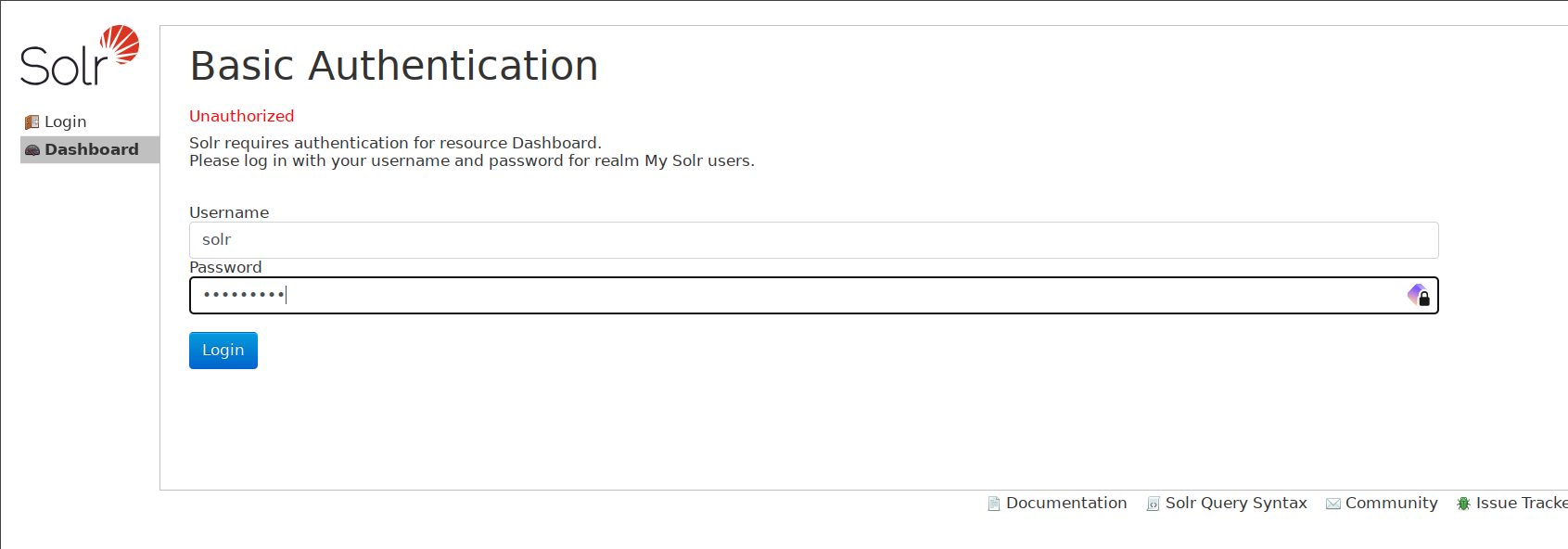
Introduceți utilizatorul solr și parola solrRocks și veți obține tabloul de bord Apache Solr.
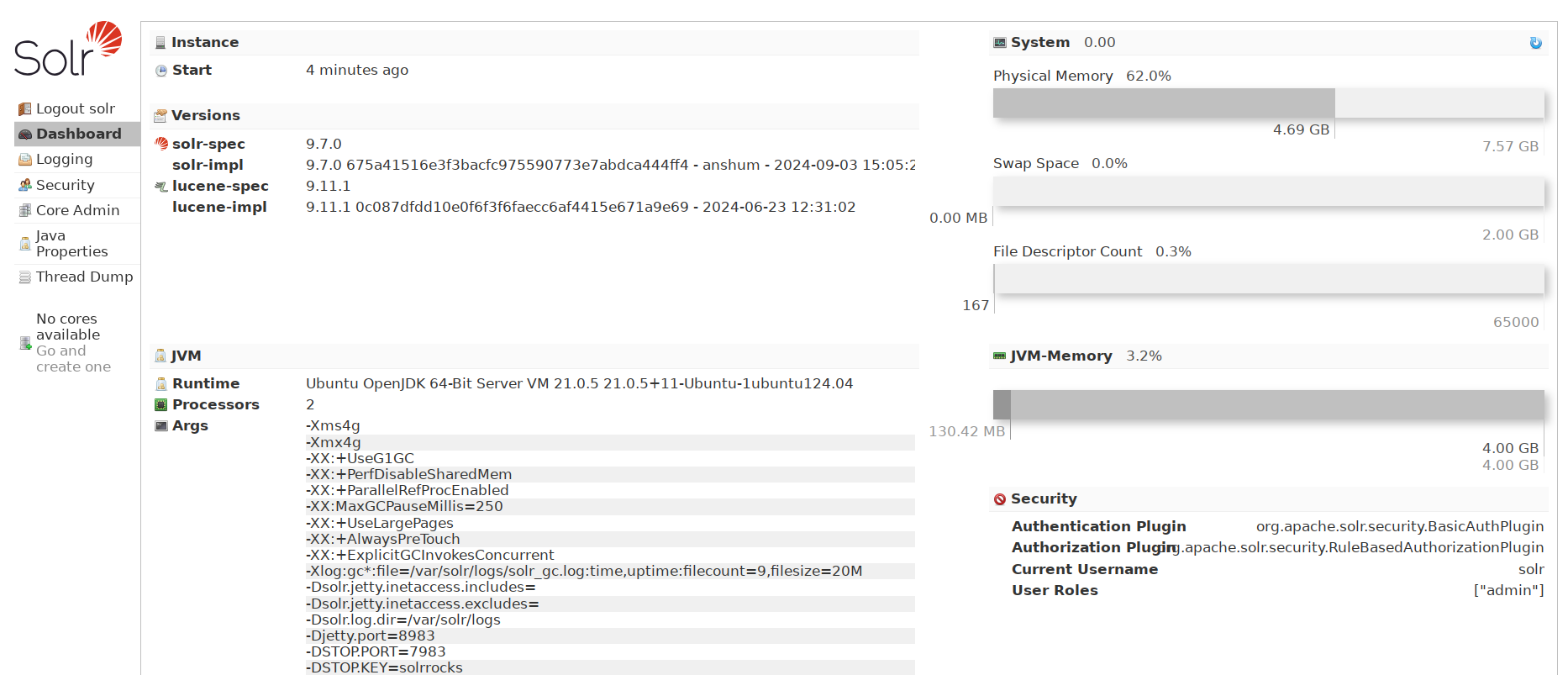
Crearea primei colecții în Apache Solr
În această etapă, ați configurat și securizat Apache Solr. Acum veți crea Prima Colecție în Apache Solr din linia de comandă.
Deschideți din nou fișierul /etc/default/solr.in.sh cu editorul vim.
sudo vim /etc/default/solr.in.sh
Decomentați liniile SOLR_AUTH_TYPE și SOLR_AUTHENTICATION_OPTS și lăsați-le pe ambele ca implicite.
SOLR_AUTH_TYPE="de bază" SOLR_AUTHENTICATION_OPTS="-Dbasicauth=solr:SolrRocks"
Salvați fișierul și ieșiți din editor.
Acum rulați următoarea comandă pentru a reporni serviciul Apache Solr.
sudo systemctl restart solr
Apoi, rulați comanda de mai jos pentru a crea prima colecție cu numele my_first_index.
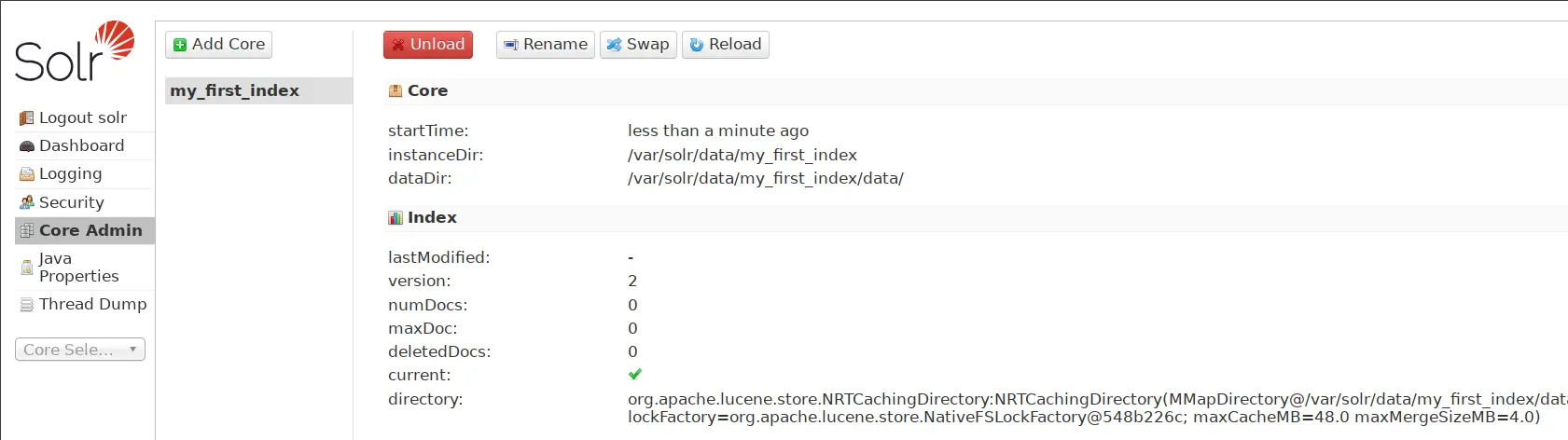
su - solr -c "/opt/solr/bin/solr create -c my_first_index -n MyIndex"
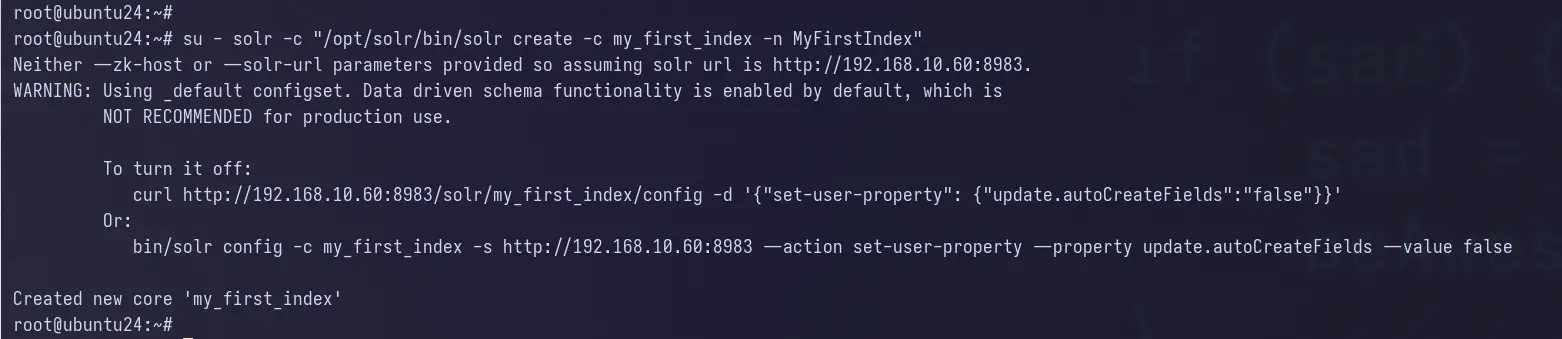
Acum treceți la Apache Solr Dashboard și veți vedea noua colecție my_first_index a fost creată.