Situatie
The Linux curl command can do a whole lot more than download files. Find out what curl is capable of, and when you should use it instead of wget.
curl vs. wget : What’s the Difference?
People often struggle to identify the relative strengths of the wget and curl commands. The commands do have some functional overlap. They can each retrieve files from remote locations, but that’s where the similarity ends. wget is a fantastic tool for downloading content and files. It can download files, web pages, and directories. It contains intelligent routines to traverse links in web pages and recursively download content across an entire website. It is unsurpassed as a command-line download manager. curl satisfies an altogether different need.
Yes, it can retrieve files, but it cannot recursively navigate a website looking for content to retrieve. What curl actually does is let you interact with remote systems by making requests to those systems, and retrieving and displaying their responses to you. Those responses might well be web page content and files, but they can also contain data provided via a web service or API as a result of the “question” asked by the curl request.
And curl isn’t limited to websites. curl supports over 20 protocols, including HTTP, HTTPS, SCP, SFTP, and FTP. And arguably, due to its superior handling of Linux pipes, curl can be more easily integrated with other commands and scripts. The author of curl has a webpage that describes the differences he sees between curl and wget.
Solutie
How to Install curl
Out of the computers used to research this article, Fedora 31 and Manjaro 18.1.0 had curl already installed. curl had to be installed on Ubuntu 18.04 LTS. On Ubuntu, run this command to install it:
sudo apt-get install curl
![]()
The curl Version
The –version option makes curlreport its version. It also lists all the protocols that it supports.
curl –version

Retrieving a Web Page with curl
If we point curl at a web page, it will retrieve it for us.
curl https://www.bbc.com
![]()
But its default action is to dump it to the terminal window as source code.
Saving Data to a File
Let’s tell curl to redirect the output into a file:
curl https://www.bbc.com > bbc.html
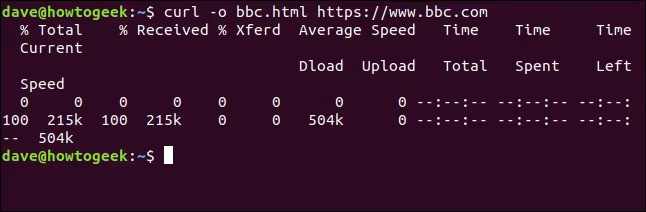
This time we don’t see the retrieved information, it is sent straight to the file for us. Because there is no terminal window output to display, curl outputs a set of progress information. It didn’t do this in the previous example because the progress information would have been scattered throughout the web page source code, so curl automatically suppressed it. In this example, curl detects that the output is being redirected to a file and that it is safe to generate the progress information.

The information provided is:
- % Total: The total amount to be retrieved.
- % Received: The percentage and actual values of the data retrieved so far.
- % Xferd: The percent and actual sent, if data is being uploaded.
- Average Speed Dload: The average download speed.
- Average Speed Upload: The average upload speed.
- Time Total: The estimated total duration of the transfer.
- Time Spent: The elapsed time so far for this transfer.
- Time Left: The estimated time left for the transfer to complete Current Speed:
- The current transfer speed for this transfer.
Because we redirected the output from curl to a file, we now have a file called “bbc.html.”
Double-clicking that file will open your default browser so that it displays the retrieved web page.
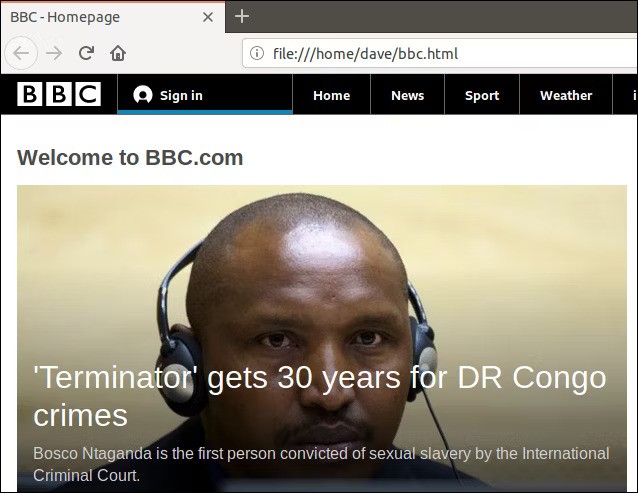
Note that the address in the browser address bar is a local file on this computer, not a remote website.
We don’t have to redirect the output to create a file. We can create a file by using the -o (output) option, and telling curl to create the file. Here we’re using the -o option and providing the name of the file we wish to create “bbc.html.”
curl -o bbc.html https://www.bbc.com
Leave A Comment?