Situatie
Solutie
Modifying a Python list while you’re looping through it might sound like a clever shortcut, but it’s a classic Python gotcha! This sneaky mistake can lead to unexpected behavior, like skipping elements or ending up with a completely messed-up list.
Let’s say we have a list of numbers, and we want to remove all numbers less than 5. Sounds straightforward, right?
numbers = [1, 2, 6, 3, 7, 4, 8, 5]
print(“Original list:”, numbers)
for number in numbers:
if number < 5:
numbers.remove(number)
print(“Modified list (oops!):”, numbers)
If you run this code, you’ll find that the number 2 remains on the list.
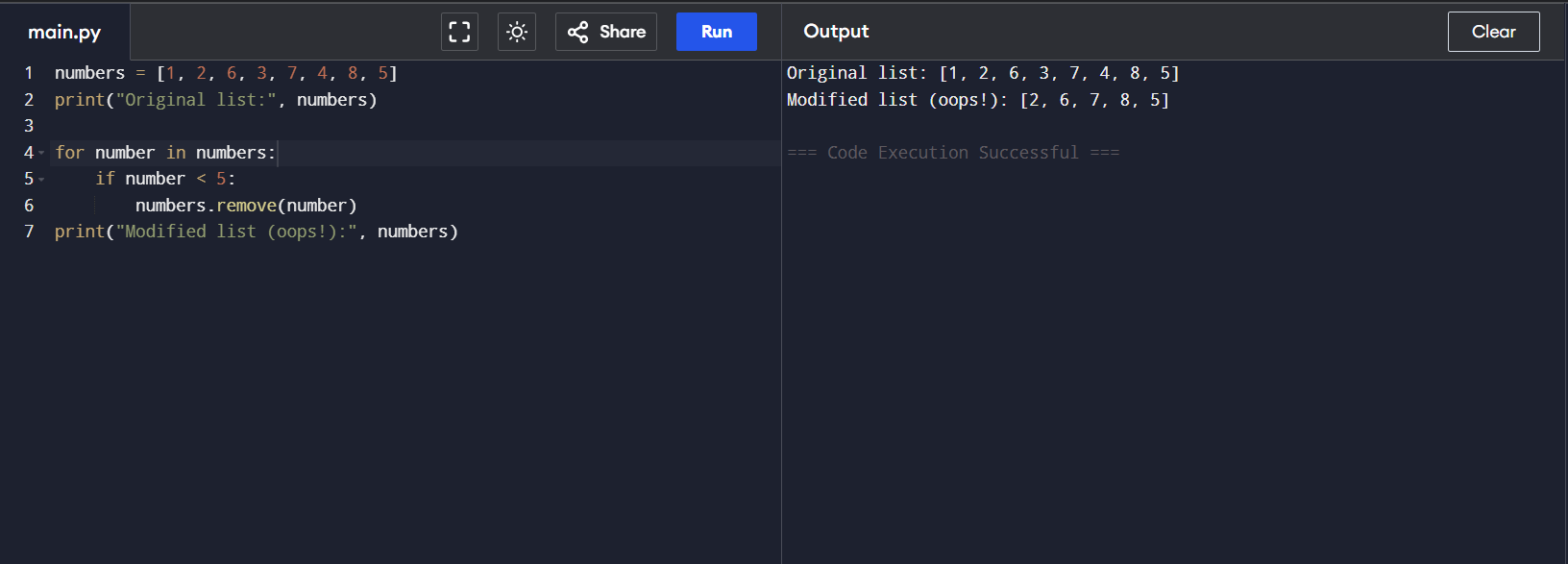
In this code, we’re trying to iterate through numbers and remove elements that are less than 5. However, when we remove an element, the list shrinks, and the indices of the subsequent elements shift. This can cause the loop to skip over elements. For example, when 1 is removed, 2 moves into 1’s old position, but the loop’s internal counter has already moved on, potentially skipping 2.
The safest and most common way to modify a list based on its elements is to iterate over a copy of the list or to build a new list with only the elements you want to keep. In the copy approach, we create a shallow copy of the list before iterating. This way, you can remove elements from the original list without affecting the iteration process.
numbers = [1, 2, 6, 3, 7, 4, 8, 5]
print(“Original list:”, numbers)
for number in numbers[:]: # Iterate over a slice (copy) of the list
if number < 5:
numbers.remove(number)
print(“Modified list (fixed with copy):”, numbers)
By using numbers[:], we create a slice of the numbers list, which is a shallow copy. The for loop then iterates over this copy, completely independent of any modifications we make to the original numbers list.
Often, a more Pythonic way to achieve this is to create a new list containing only the items you want to keep. This approach avoids in-place modification altogether and is often more efficient.
numbers = [1, 2, 6, 3, 7, 4, 8, 5]
print(“Original list:”, numbers)
filtered_numbers = [number for number in numbers if number >= 5]
print(“Filtered list (new list method):”, filtered_numbers)
In this code, we use list comprehension to create a new list from the original one that contains our desired elements. This also keeps the original list intact.
5 Naming Conflicts
Choosing variable and file names might seem like a small detail until Python turns around and bites you (figuratively.) Naming things poorly can lead to weird bugs, shadowed functionality, and hours of confusion. There are two common ways this happens: using Python keywords or built-in names as your own, and accidentally naming your scripts after existing Python modules.
Python won’t stop you from naming a variable list, str, or even sum. But just because you can, doesn’t mean you should.
list = [1, 2, 3]
print(list)
This code will run without any issues. However, if you add another line that contains the list() function in Python, you get an error.
list = [1, 2, 3]
print(list)
list = list(‘123’)
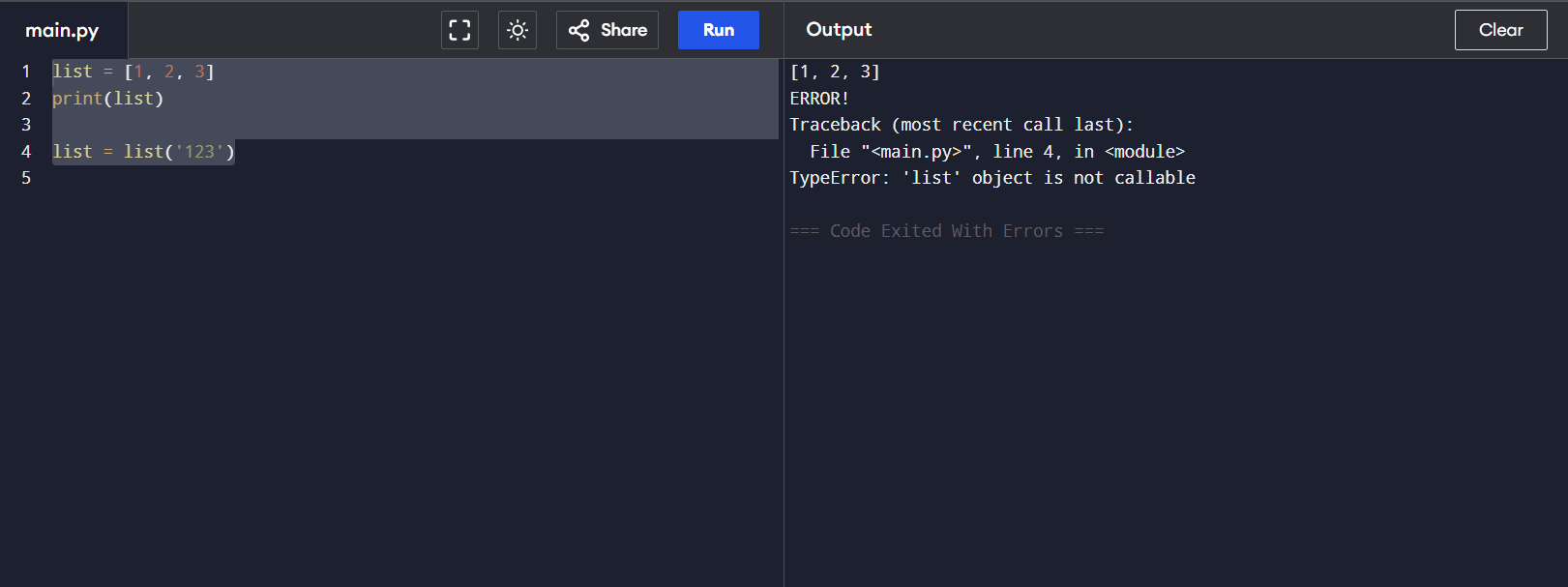
That’s because you’ve overwritten the built-in list() function with your own list object. When you try to call list(‘123’), Python thinks you’re trying to call your own list, not the built-in function. So, always use descriptive names that don’t clash with Python’s core features.
numbers = [1, 2, 3]
converted = list(‘123’)
Not only will this help you avoid using reserved keywords, but it’s also good practice for code readability and debugging. The same goes for naming your script files. Let’s say you create a file named random.py to experiment with random numbers:
# random.py
import random
print(random.randint(1, 10))
But when you run this, you’ll likely see an error complaining that “module ‘random’ has no attribute ‘randint’.” Python is importing your own file (random.py) instead of the actual random module from the standard library. Classic shadowing bug.
Avoid naming your scripts after existing modules like random.py, math.py, os.py, or json.py. And if you accidentally do it, don’t forget to delete the corresponding .pyc or __pycache__ folders after renaming.
4 Mutable Function Arguments
Python lets you set default values for function arguments, which is super convenient. But when those default values are mutable (like lists or dictionaries), you’re walking into a sneaky bug trap.
The default mutable object is created only once, when the function is defined, not each time it’s called. That means if it gets modified, that change sticks around for the next call.
def add_item_to_list(item, item_list=[]):
item_list.append(item)
return item_list
print(add_item(“apple”))
print(add_item(“banana”))
When you run this code, you might expect each call to add_item_to_list() to start with a fresh, empty list if you don’t provide one. However, the output will show something unexpected:
We called the function twice. So why is “apple” still there on the second call? The list item_list is only created once, so every call to the function keeps modifying the same list. This leads to surprising and very buggy behavior. To fix this, you can use None as the default and create the list inside the function:
def add_item_to_list(item, item_list=None):
if item_list is None:
item_list = []
item_list.append(item)
return item_list
print(add_item(“apple”))
print(add_item(“banana”))
By defaulting to None, a new list is created every time the function is called.
3 Handling Files the Wrong Way
Working with files in Python is pretty easy. But there’s a common mistake that can sneak into your code. Not closing the file. It might seem harmless, but leaving files open can lead to memory leaks, file corruption, or locked files that can’t be accessed by other programs.
file = open(‘data.txt’, ‘r’)
content = file.read()
print(content)
# Forgot to close the file!
Leaving files open can cause serious trouble. It can even prevent the file from being deleted or modified by other processes. That’s why you should always make sure to close the file after you finish your operations. You can do so using the close() function.
file = open(‘data.txt’, ‘r’)
content = file.read()
print(content)
file.close()
Another best practice is to use Python’s with statement, which automatically takes care of closing the file for you.
with open(‘data.txt’, ‘r’) as file:
content = file.read()
print(content)
The with block handles all the behind-the-scenes cleanup. As soon as you exit the block, Python closes the file for you. This allows you not to worry about manually closing the file yourself.
2 Importing Everything From a Module
As a beginner, it’s tempting to just slap a from module import * at the top of your script and call it a day. But as your code grows, this shortcut becomes a recipe for disaster.
from math import *
from custom_math import *
print(sqrt(16))
What if both math and custom_math define a function called sqrt()? Which one gets called? Python doesn’t tell you. It just silently overrides the earlier one.
You could be using a completely different function without realizing it. Moreover, in large codebases, debugging becomes a nightmare in large codebases. You lose track of where functions or classes are coming from. That’s why you should be explicit with your imports.
import math
import custom_math
print(math.sqrt(16))
print(custom_math.sqrt(16))
Or even like this:
from math import sqrt as m_sqrt
from custom_math import sqrt as c_sqrt
print(m_sqrt(16))
print(c_sqrt(16))
Explicit is better than implicit (a core idea from the Zen of Python.) You always know what you’re using and where it came from.
1 Proper Exception Handling
Even the most carefully crafted code can run into unexpected problems. These are called exceptions in Python. Handling them gracefully is what makes your program robust. However, many beginners approach exception handling with a “catch-all” mentality, using broad except clauses. It might silence the error for now, but it leaves your code fragile, confusing, and hard to debug.
try:
result = 10 / 0
except:
print(“Something went wrong!”)
This catches everything. Even errors you didn’t expect or want to handle. Syntax errors, keyboard interrupts, typos, broken imports. Python will swallow them all with that generic except. This isn’t ideal. Instead, be specific about what you’re catching:
try:
result = 10 / 0
except ZeroDivisionError:
print(“You can’t divide by zero!”)
You’re catching only the error you expect. If something else goes wrong, Python will still raise it. So you won’t silently ignore real bugs. You can also handle multiple exceptions smartly:
try:
value = int(input(“Enter a number: “))
result = 10 / value
except ValueError:
print(“That’s not a valid number!”)
except ZeroDivisionError:
print(“You can’t divide by zero!”)
Avoid except: by itself. If you must catch all exceptions (rarely), use except Exception: and still handle it carefully. By handling exceptions specifically, your code becomes more predictable, easier to debug, and capable of providing more meaningful feedback.