Situatie
Solutie
Using a web address or uniform resource locator (URL) in a script involves a leap of faith. There are all sorts of reasons why trying to use the URL might fail.
The URL could have typos in it, especially if the URL is passed as a parameter to the script.The URL might be out of date. The online resource it points to might be temporarily offline, or it might have been removed permanently.
Checking whether the URL exists and responds properly before attempting to use it is good working practice. Here are some methods you can use to verify it’s safe to proceed with a URL, and gracefully handle error conditions.
Using wget to Verify a URL
The wget command is used to download files, but we can suppress the download action using its –spider option. When we do this, wget gives us useful information about whether the URL is accessible and responding.
We’ll try to see whether google.com is up and active, then we’ll try a fictional URL of geegle.com. We’ll check the return codes in each case.
wget --spider https://www.google.com
echo $?
wget --spider https://www.geegle.com
echo $?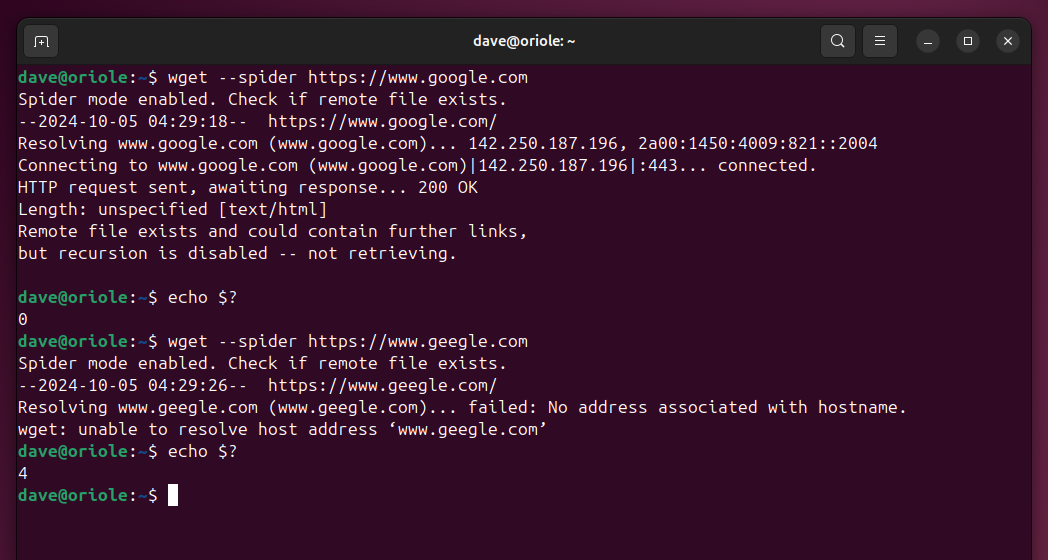
As we can see, wget lets us know that Google is alive and well, while Geegle (unsurprisingly) isn’t. Also, note that the exit code in the successful case is zero, and in the unsuccessful case it’s four.
Zero means success, anything else means there’s some sort of problem. We can use those values in our script to control the execution flow.
You can’t fail to notice wget sends a lot of output to the screen. We can suppress the output with the -q (quiet) option.
wget --spider -q https://www.google.com
echo $?
wget --spider -q https://www.geegle.com
echo $?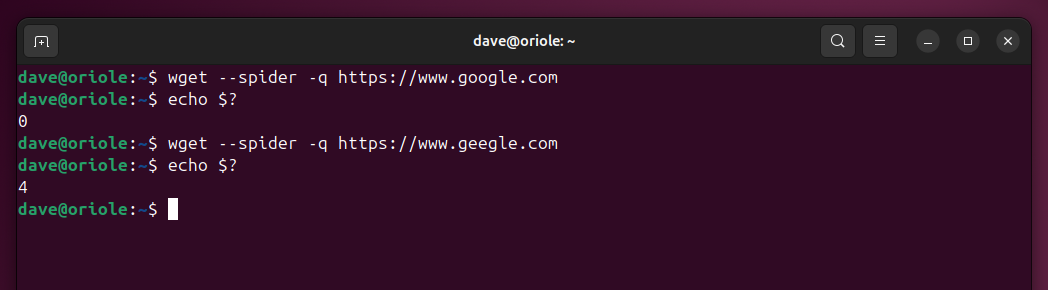
Open your favorite editor, copy these lines into it, and save it as url-1.sh.
#!/bin/bash
if wget --spider -q https://www.google.com; then
echo "The URL exists and is accessible."
else
echo "Can't access that URL."
fiYou’ll need to make the script executable.
chmod +x url-1.sh
You’ll need to do that with all the scripts discussed here. Use the appropriate script name in each case. Let’s run our script.
./url-1.sh
The if comparison test detects the zero response from the wget command and executes the first clause of the if statement. If you edit the script and change the URL to something like https://www.geegle.com, it’ll report a failure.
./url-1.sh
There are eight different responses that wget can generate, seven of which are error conditions.
0: No problems occurred.
1: Generic error code.
2: Error parsing the command-line options.
3: File I/O error.
4: Network failure.
5: SSL verification failure.
6: Username/password authentication failure.
7: Protocol errors.
8: The server issued an error response.
The cURL command expands on this. It can show the HTTP response code from the URL (or, more correctly, from the web server hosting the URL).
Isolating the HTTP Response Code
You might need to install the cURL command. You’ll find it in the repositories for your distribution.
On Ubuntu use:
sudo apt install curlOn Fedora, type:
sudo dnf install curlOn Manjaro and Arch, the command is:
sudo pacman -S curlLet’s point cURL at Google and see what we get. The –head option tells curl to retrieve just the header information from the website, rather than downloading the entire webpage. The –silent option doesn’t suppress cURL’s output, it stops cURL from reporting on its progress.
curl --head --silent https://www.google.com
echo $?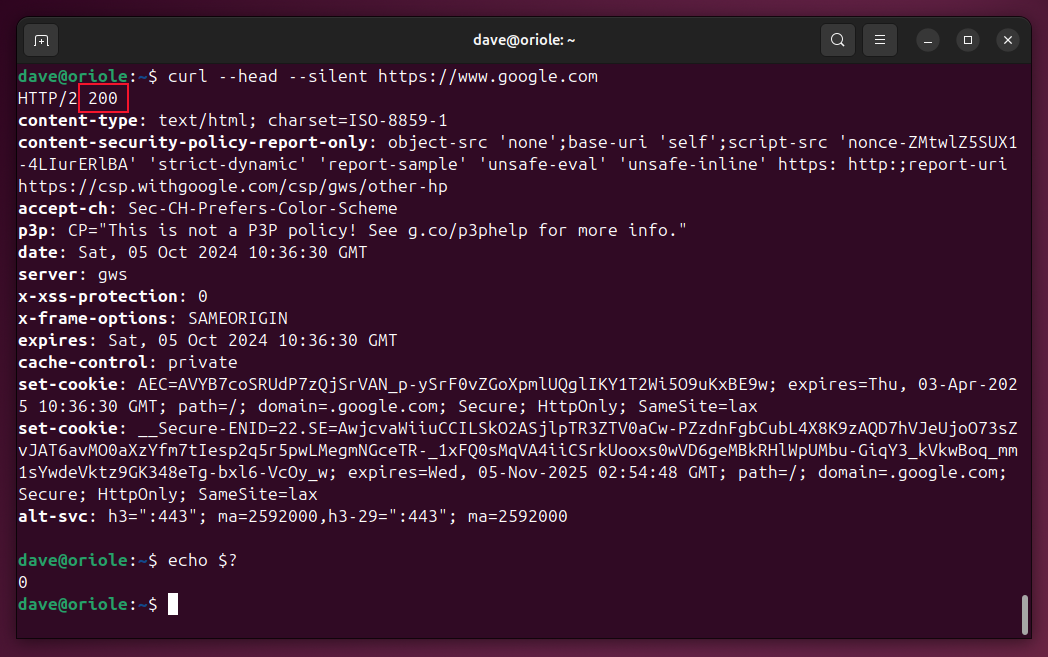
The exit code of zero is cURL telling us everything was OK, but the response we’re after is the actual HTTP code from the server. That’s the 200 in the first line of output. In HTTP parlance, 200 means success.
We can refine cURLs behavior by directing it’s output to /dev/null so it runs silently, and then partially countermand that by using the –write-out option to send the HTTP response code to the terminal window.
curl --head --silent --output /dev/null --write-out '%{http_code}' https://www.google.com
Now we’ve got the HTTP response code, we can use it in a script.
Using cURL to Verify a URL
This script assigns the HTTP response code to a variable called result. Copy this to your editor, save it as url-2.sh, then use chmod to make it executable.
result=$(curl –head –silent –write-out “%{http_code}” –output /dev/null https://www.google.com)
if [[ $result -eq 200 ]]; then
echo “The URL exists and is accessible.”
else
echo “Can’t access that URL.”
fi
The if comparison test checks the variable against the value 200. If it matches, the script executes the first clause of the if statement. Any other value is treated as an error condition and the second clause is executed.
./url-2.sh
Handling Different Error Conditions
Now that we’ve got a way to retrieve the HTTP code, we can expand on our script’s ability to deal with different error conditions.
#!/bin/bash
target="https://www.google.com"
result=$(curl --head --silent --output /dev/null --write-out '%{http_code}' "$target")
case $result in
200)
echo "The URL exists and is accessible."
;;
301)
echo "HTTP error 301. The resource has been permanently relocated."
;;
403)
echo "HTTP error 403. The server heard you, but won't comply."
;;
404)
echo "HTTP error 404. The classic Page Not Found."
;;
000)
echo "No response from server."
;;
*) # anything not captured in the above list
echo "HTTP error $result."
;;
esacThe URL is assigned to a variable called target. That variable is used in the cURL command. If you have a very long URL, this makes the script easier to read.
The HTTP code is captured in a variable called result. This is used in a case statement. This structure allows you to have dedicated sections handling specific error types. The final case ‘*)’ captures all error conditions that aren’t handled by a dedicated case.
Copy this to your editor, save it as url-3.sh, and use chmod to make it executable.
./url-3.sh
./url-3.sh
./url-3.sh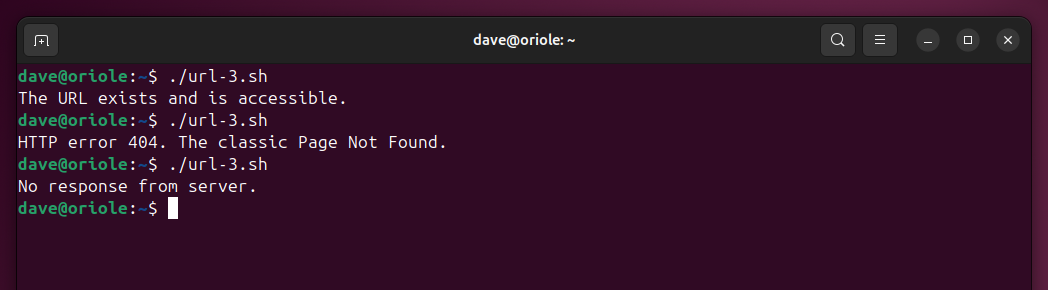
Our script now responds to a range of HTTP response codes.
Handling Timeouts
Another scenario our script ought to deal with, is avoiding long pauses waiting for a response from a slow web server.
We can add two more options to the cURL command line. The –connect-timeout option sets a limit on the time cURL will wait for a connection to be made.
The –max-time timeout specifies the total amount of time cURL will spend executing the command. Note that the –max-time timeout will trigger even if the command is working and is still in progress. If you use it, experiment on the command line to establish a safe time value to use.
We can add these options to the cURL command like this:
curl --head --connect-timeout 8 --max-time 14 --silent --output /dev/null --write-out '%{http_code}' https://www.google.com
Leave A Comment?