Situatie
One of the critical issues while training a neural network on the sample data is Overfitting. When the number of epochs used to train a neural network model is more than necessary, the training model learns patterns that are specific to sample data to a great extent. This makes the model incapable to perform well on a new dataset. This model gives high accuracy on the training set (sample data) but fails to achieve good accuracy on the test set. In other words, the model loses generalization capacity by overfitting to the training data.
Solutie
Pasi de urmat
Finding the optimal number of epochs to avoid overfitting on MNIST dataset. Loading dataset and preprocessing:
Building a CNN model:
Summary of the model:
Compiling the model with RMSprop optimizer, categorical cross entropy loss function and accuracy as success metric
Creating validation set and training set by partitioning the current training set:
val_images = train_images[:10000]
partial_images = train_images[10000:]
val_labels = y_train[:10000]
partial_labels = y_train[10000:]
Initializing earlystopping callback and training the model:
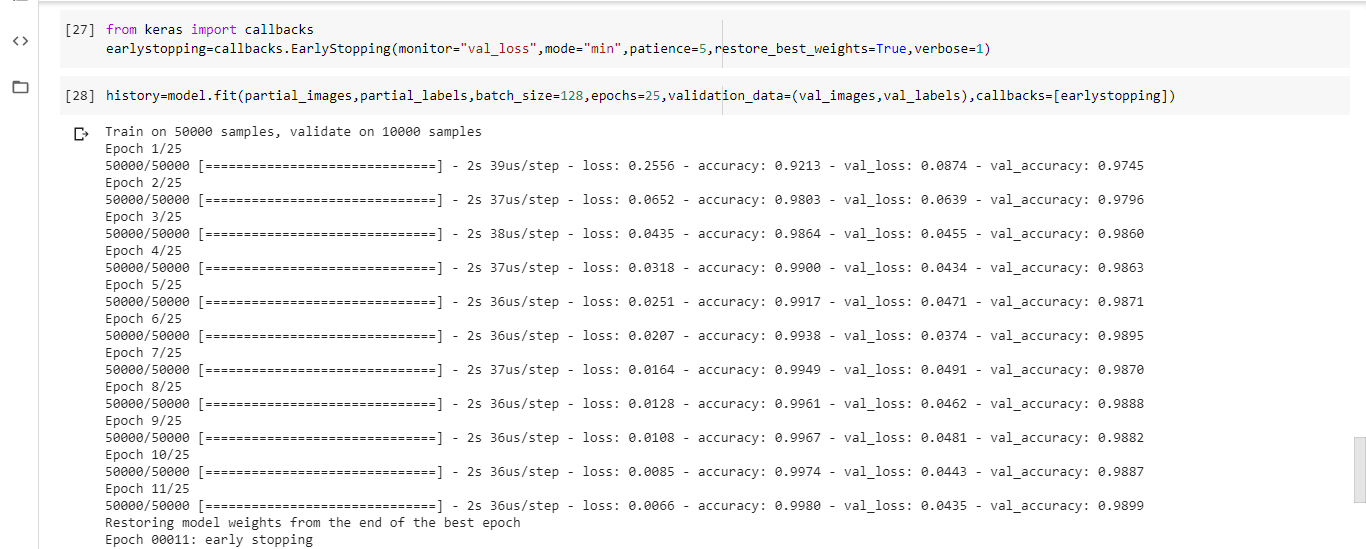
Training stopped at 11th epoch i.e., the model will start overfitting from 12th epoch. Therefore, the optimal number of epochs to train most dataset is 11.
Training stopped at 11th epoch i.e., the model will start overfitting from 12th epoch. Therefore, the optimal number of epochs to train most dataset is 11.
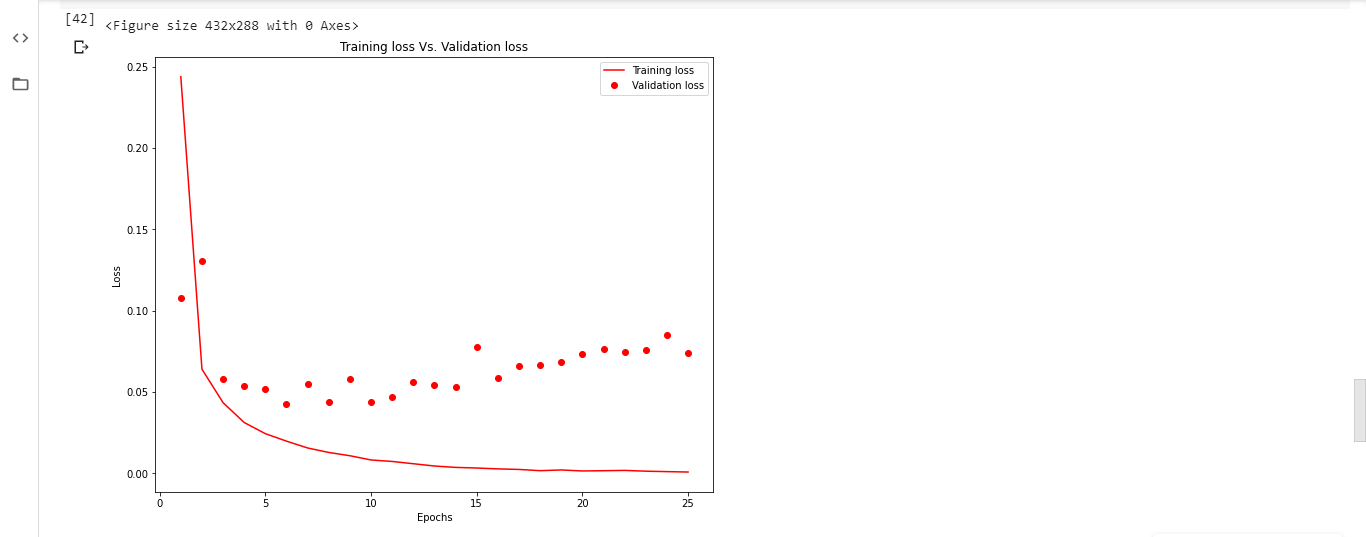
Observing loss values without using Early Stopping call back function:
Train the model up until 25 epochs and plot the training loss values and validation loss values against number of epochs. The plot looks like
Leave A Comment?