Cum se instalează Jupyter Notebook cu proxy Nginx pe Debian 12
Jupyter este o aplicație web gratuită și open-source pentru calcul interactiv și știința datelor. Jupyter este compatibilă cu toate limbajele de programare și oferă mai multe programe software, cum ar fi JupyetrLab, care oferă un mediu de editare multi-notebook bogat în funcții și cu file, Notebook ca o modalitate ușoară și simplificată de creare a notelor, Qtconsole și multe altele.
Înainte de a începe, asigurați-vă că aveți următoarele:
- Un server Debian 12
- Un utilizator non-root cu privilegii de administrator
- Un nume de domeniu a indicat adresa IP a serverului
Instalarea pachetelor Python
Înainte de a instala Jupyter, trebuie să instalați Python, managerul de pachete Pip Python, venv pentru crearea unui mediu virtual Python și git. În această secțiune, veți instala aceste pachete cu ajutorul managerului de pachete APT.
Pentru a începe, executați comanda de mai jos pentru a actualiza indexul pachetului Debian.
actualizare sudo apt

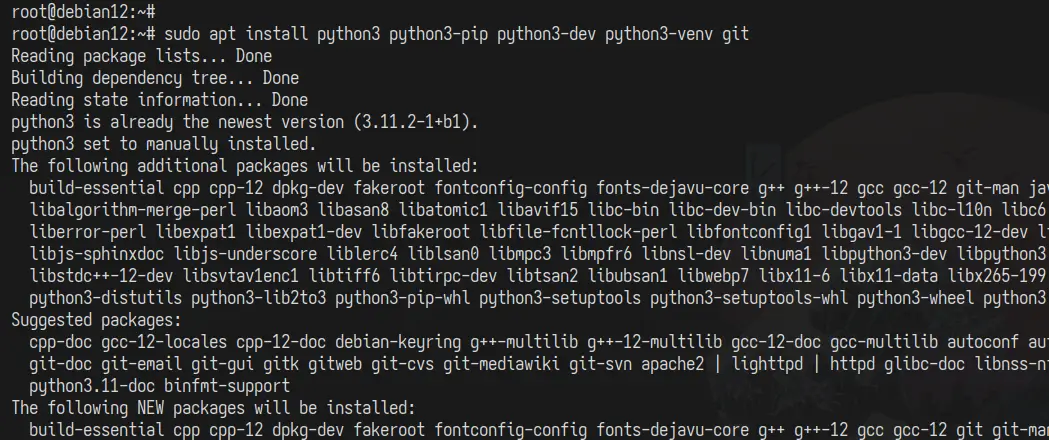
Acum instalați Python și dependențele precum Pip, venv și pachetul Python Dev. Introduceți „ Y ” pentru a confirma instalarea.
sudo apt instalează python3 python3-pip python3-dev python3-venv git
După finalizarea instalării, executați comanda „ pip3 ” de mai jos pentru a actualiza versiunea de Pip.
pip3 instalează --break-system-package --upgrade pip
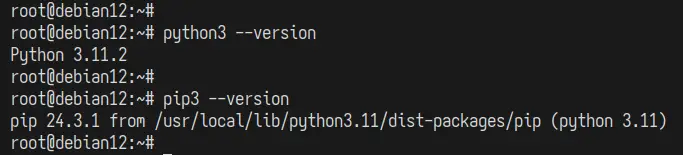
Acum verificați versiunea Python și Pip cu comanda de mai jos.
python3 --version pip3 --version
Puteți vedea mai jos că sunt instalate Python 3.11 și Pip 24.3 .
Configurarea mediului virtual Python
După ce ați instalat Python și alte dependențe, veți crea un nou mediu virtual Python pentru instalarea Jupyter. Astfel, instalarea Jupyter va fi izolată în mediul virtual. De asemenea, aveți nevoie de un utilizator Linux dedicat, așa că asigurați-vă că aveți utilizatorul pregătit.
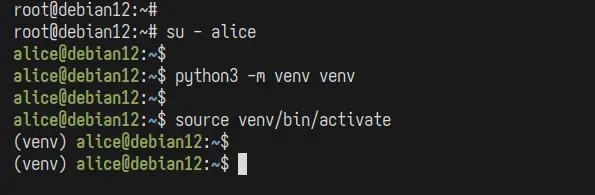
Conectați-vă la utilizatorul dvs. cu comanda de mai jos.
su - nume de utilizator
Rulați comanda „ python3 ” de mai jos pentru a crea un nou mediu virtual Python, „ venv ”. Aceasta va instala Python și Pip în mediul dvs. virtual, care este separat de sistemul dvs.
python3 -m venv venv
Activați mediul virtual Python „ venv ”. Odată activat, promptul shell va deveni de genul „ (venv) numeutilizator@gazdă … ”.
sursă venv/bin/activate
Dacă doriți să dezactivați „ venv ”, executați comanda „ deactivate ” de mai jos.
deactivate
Instalarea Jupyter
Acum că ați creat și activat mediul virtual Python, puteți începe instalarea Jupyter prin intermediul managerului de pachete Pip Python.
Pentru a instala Jupyter, executați comanda „ pip3 ” de mai jos.
pip3 install jupyter
Mai jos puteți vedea instalarea Jupyter într-un mediu virtual.
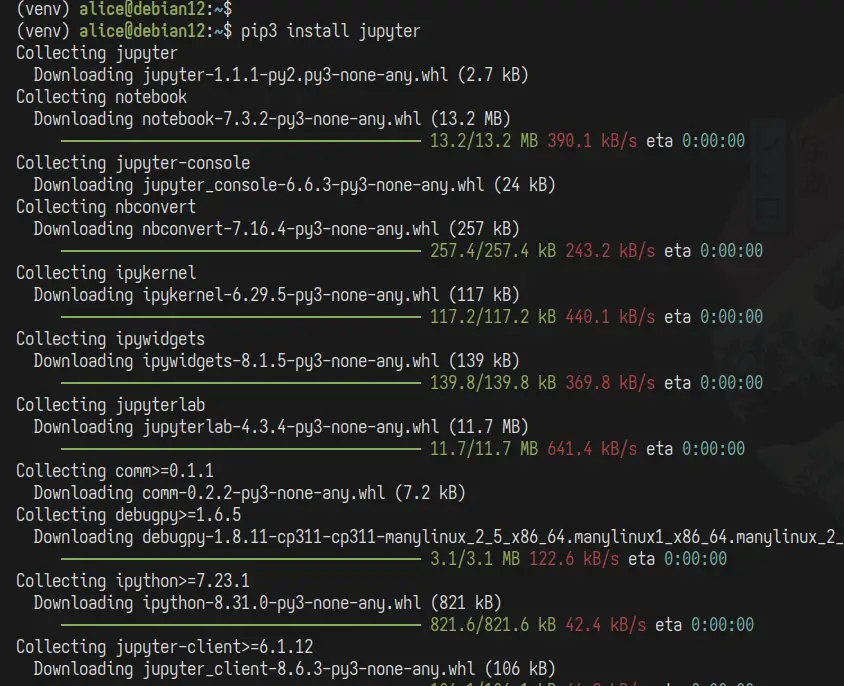
După finalizarea instalării, verificați versiunea Jupyter cu următoarea comandă.
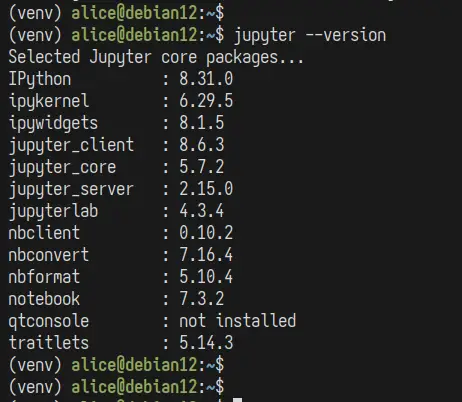
jupyter --version
În rezultatul următor, puteți vedea versiunea fiecărei componente Jupyter instalate.
Activați autentificarea în Jupyter Notebook
După ce ați instalat Jupyter, veți configura instalarea Jupyter Notebook activând autentificarea prin parolă.
Mai întâi, executați comanda de mai jos pentru a genera configurația pentru Jupyter Notebook. Aceasta va genera o nouă configurație pentru „ ~/.jupyter/jupyter_notebook_config.py ”.
jupyter notebook --geenrate-config
Acum setați parola pentru Jupyter Notebook folosind comanda de mai jos. Introduceți parola când vi se solicită și repetați.
jupyter notebook password
În cele din urmă, executați comanda „ deactivate ” pentru a vă deconecta din mediul virtual „venv”.
deactivate
Rularea Jupyter Notebook ca serviciu Systemd
În această secțiune, veți crea un nou serviciu systemd care va rula Jupyter Notebook. Astfel, Jupyter Notebook va rula în fundal ca serviciu systemd și îl puteți gestiona cu ușurință cu utilitarul „ systemctl ”.
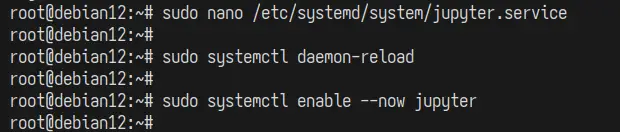
Creați un nou fișier de serviciu systemd „ /etc/systemd/system/jupyter.service ” cu următorul editor „ nano ”.
sudo nano /etc/systemd/system/jupyter.service
Introduceți configurația de mai jos pentru a rula Jupyter Notebook ca serviciu systemd.
[Unitate] Descriere=Jupyter Notebook
[Unit] Description=Jupyter Notebook [Service] Type=simple PIDFile=/run/jupyter.pid ExecStart=/home/alice/venv/bin/jupyter-notebook --config=/home/alice/.jupyter/jupyter_notebook_config.py --allow-root User=root Group=root WorkingDirectory=/home/alice/venv Restart=always RestartSec=10 [Install] WantedBy=multi-user.target
Salvați fișierul și ieșiți din editor.
Acum executați comanda „ systemctl ” de mai jos pentru a reporni managerul systemd și a aplica modificările.
sudo systemctl daemon-reload
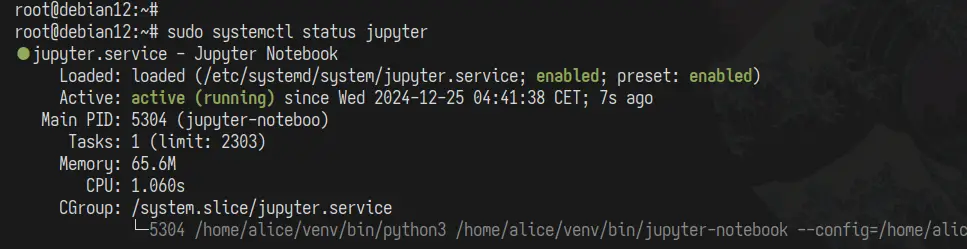
În cele din urmă, porniți și activați serviciul „ jupyter ” cu comanda de mai jos.
sudo systemctl enable --now jupyter sudo systemctl status jupyter
În următoarea ieșire, puteți vedea că serviciul „ jupyter ” rulează pe sistemul dumneavoastră.
Permiterea accesului de la distanță la Jupyter Notebook
În această secțiune, veți activa accesul de la distanță la Jupyter. Acest lucru trebuie făcut dacă doriți să configurați un proxy invers în fața instalării Jupyter.
Conectați-vă la contul de utilizator și deschideți configurația Jupyter „~/.jupyter/jupyter_notebook_config.py” cu următorul editor „nano”.
su - username nano ~/.jupyter/jupyter_notebook_config.py
Pentru a activa accesul la distanță, eliminați comentariile de la opțiunea „ c.ServerApp.allow_remote_access ” și schimbați valoarea la „ True ”.
c.ServerApp.allow_remote_access = True
Salvați și ieșiți din fișier când ați terminat.
Apoi, executați comanda „ systemctl ” de mai jos pentru a reporni serviciul „ jupyter ” și a aplica modificările. Astfel, noul token va fi generat și poate fi găsit în fișierul jurnal.
sudo systemctl restart jupyter
În cele din urmă, verificați starea serviciului „ jupyter ” cu următoarea comandă.
sudo systemctl status jupyter
Uită-te la partea de jos a mesajului și copiază token-ul generat pentru Jupyter Notebook.
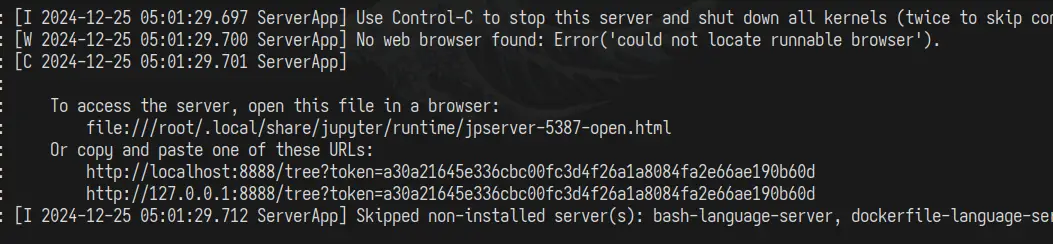
Setarea Nginx ca proxy invers
Acum, că Jupyter Notebook rulează ca serviciu, următorul pas este să instalați Nginx și să îl configurați ca proxy invers pentru Jupyter Notebook. În acest fel, puteți securiza cu ușurință Jupyter Notebook cu HTTPS.
Instalați pachetul „ nginx ” cu comanda „ apt ” de mai jos.
sudo apt install nginx -y
După finalizarea instalării, creați o nouă configurație de blocuri pentru serverul Nginx „ /etc/nginx/sites-available/jupyter ” cu următorul editor „ nano ”.
sudo nano /etc/nginx/sites-available/jupyter
Introduceți configurația de mai jos pentru a configura Nginx ca proxy invers pentru Jupyter Notebook. Asigurați-vă că schimbați parametrul „ server_name ” cu numele domeniului dvs.
server {
listen 80;
server_name lab.howtoforge.local;
access_log /var/log/nginx/howtoforge.local.access.log;
error_log /var/log/nginx/howtoforge.local.error.log;
location / {
proxy_pass http://127.0.0.1:8888;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $http_host;
proxy_http_version 1.1;
proxy_redirect off;
proxy_buffering off;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 86400;
}
}
Salvați fișierul și ieșiți din editor.
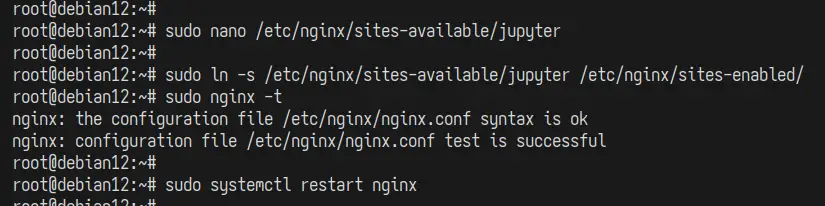
Apoi, executați comanda de mai jos pentru a activa blocul de server „ jupyter ” și a verifica configurația Nginx.
sudo ln -s /etc/nginx/sites-available/jupyter /etc/nginx/sites-enabled/ sudo nginx -t
Dacă aveți setările Nginx corecte, veți vedea un mesaj de genul „ sintaxa este ok – testul a reușit ”.
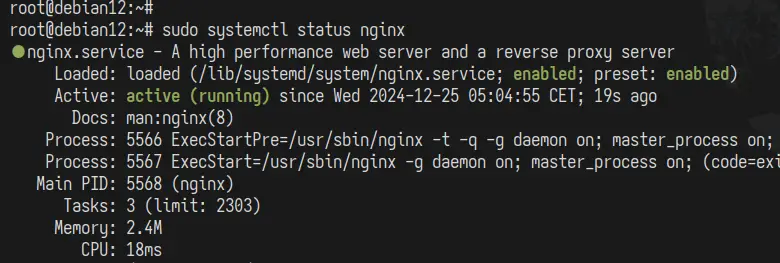
În cele din urmă, executați comanda „ systemctl ” de mai jos pentru a reporni serverul web Nginx și a verifica starea Nginx.
sudo systemctl restart nginx sudo systemctl status nginx
Dacă Nginx rulează, puteți vedea un rezultat de genul următor:
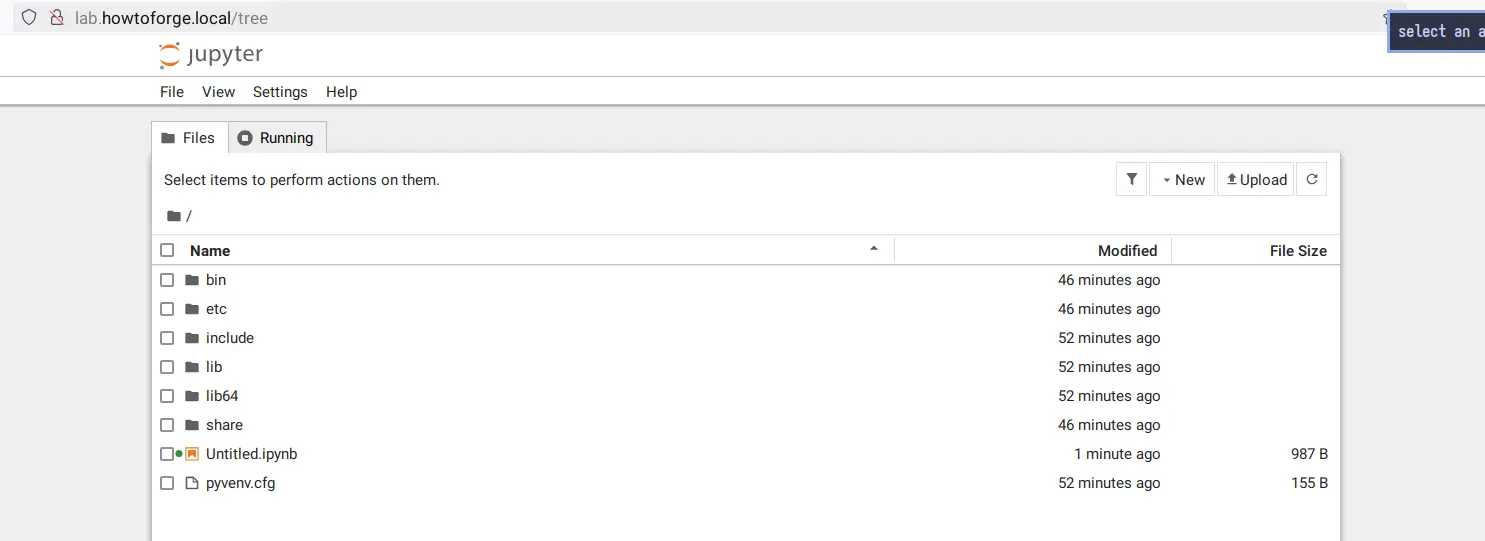
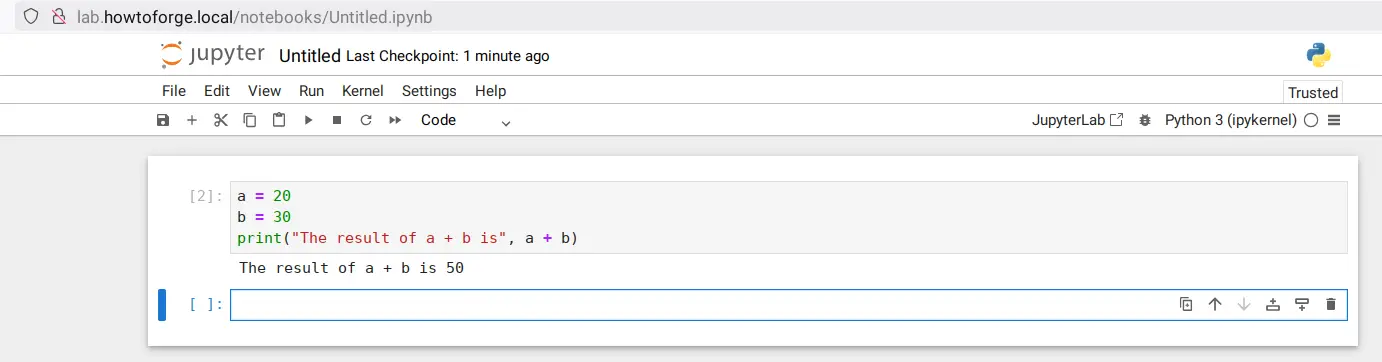
Accesarea Jupyter Notebook
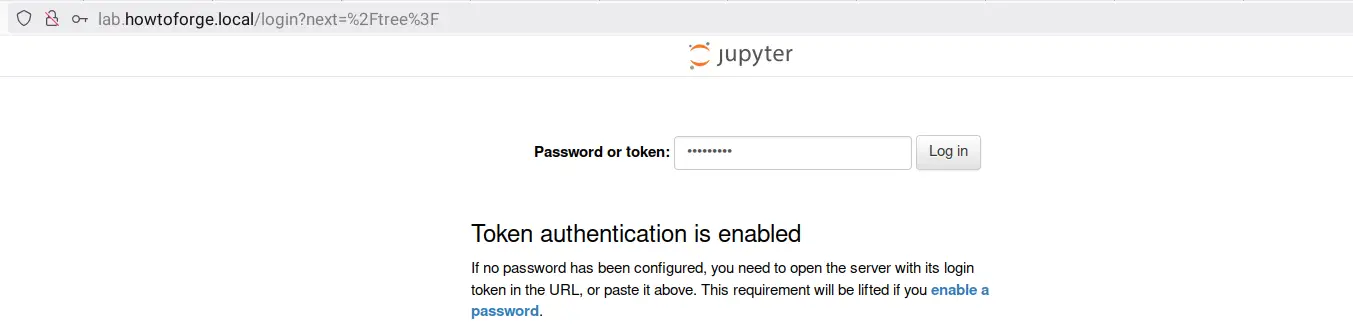
Deschideți browserul web și accesați numele de domeniu al instalării Jupyter Notebook, cum ar fi http://lab.howtoforge.local/. Dacă instalarea a reușit, vi se va solicita autentificarea cu parola Jupyter.
Introduceți parola și faceți clic pe „ Autentificare ”.
Acum veți vedea tabloul de bord Jupyter Notebook astfel: