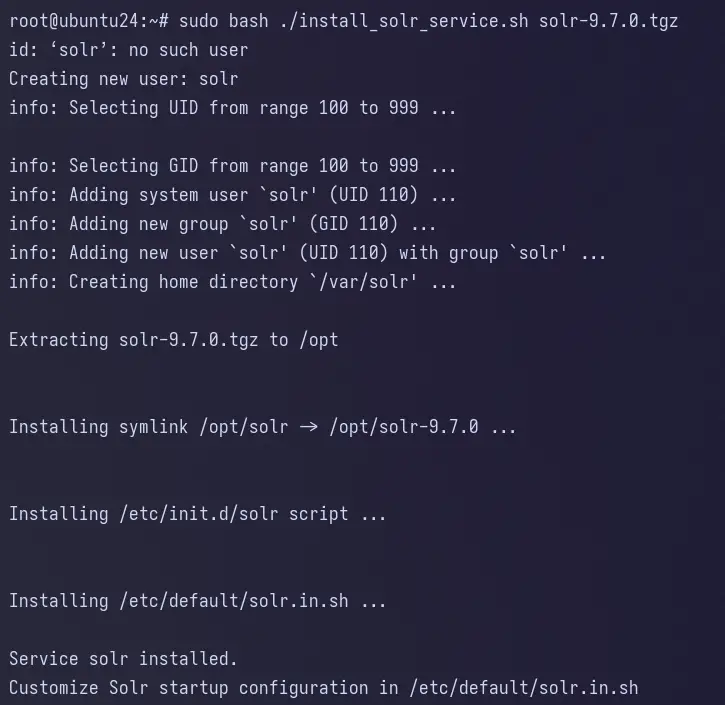
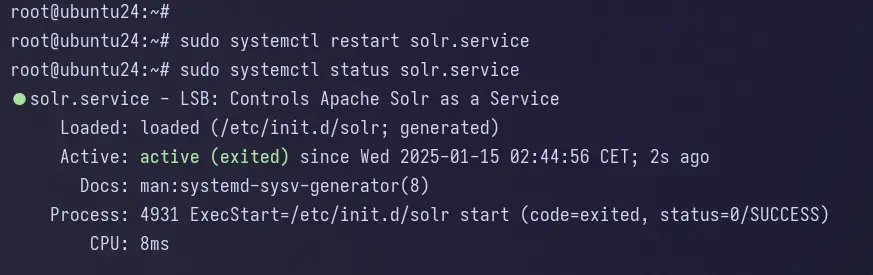
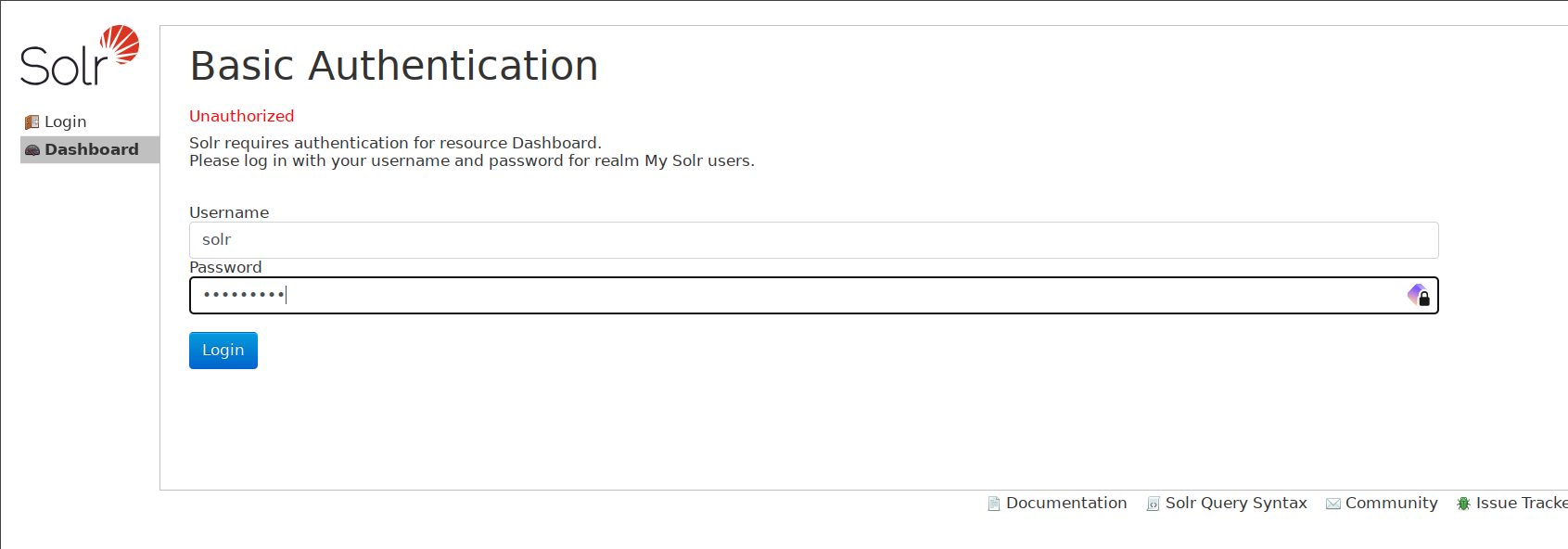
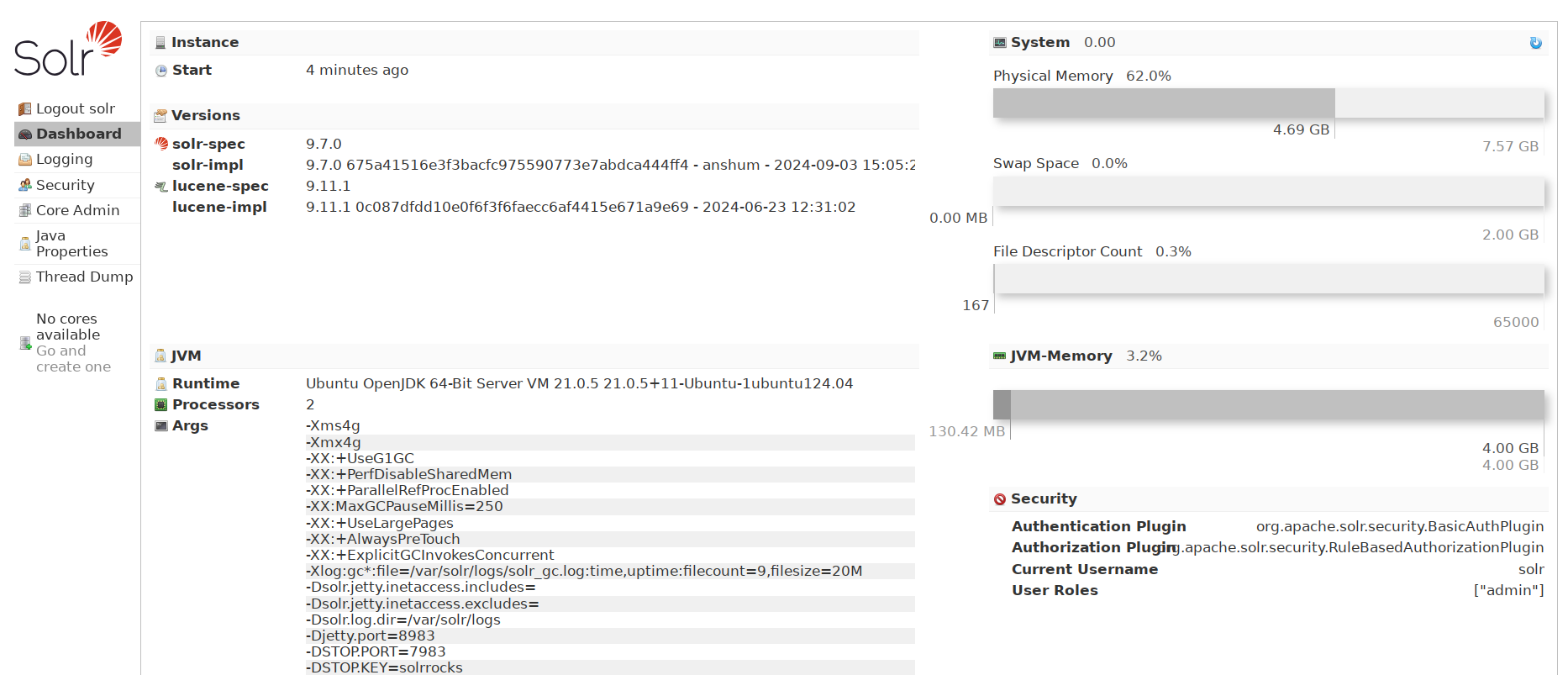
How to install Windows Server 2022
What you’ll need
-
A valid Windows Server 2022 ISO file (available from Microsoft’s Evaluation Center or Volume Licensing)
-
A bootable USB drive (8GB or more) or a virtual machine platform (e.g., Hyper-V, VMware, VirtualBox)
-
A PC or server that meets the minimum system requirements:
-
1.4 GHz 64-bit processor
-
512 MB RAM (2 GB recommended for GUI)
-
32 GB disk space
-
UEFI firmware with Secure Boot
-
Network adapter
-